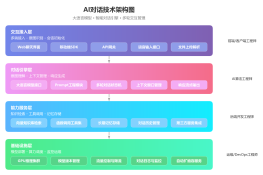
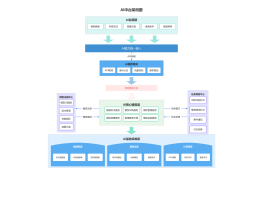
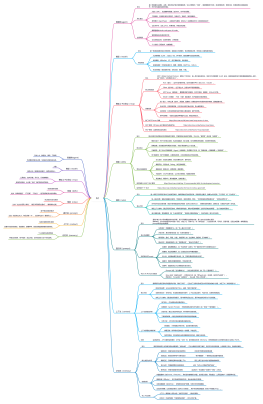
KG应用
知识库过滤
JAVA AI应用服务
回调
keyword5
标签,文件,页数,查看,下载
知识图谱关键词
系统自动关联
PG
关键词
文本向量库
余额管理
chunk1
向量搜索
Human Q
ribbon负载均衡
向量相似度取前5
运维后台
提示词token数校验
应用nginx
AI生成进度管理
标签管理
KAFKA
上传
模型获取答案
前端UI
PYTHON
记录关系
知识库关系生成【文本-向量-关键词-图谱】
记录手动删除自动关联关键词
Nebula Write
消费
:
生成Q
socketgateway
生成总结
文件管理
输入、输出、提示词、反馈、业务员、提问时间支持筛选
java知识库管理服务
阶段记录并推送
JAVA
最相关的3个
模型设置
PYAI应用
业务层
聚类算法、LLM
应用gateway
拆分后的文本块
配置补偿查询
AI对话逻辑
生成知识图谱后
文本向量
知识图谱+向量搜索(超token处理)
点赞点踩
记录本次采纳的关键词
设置:模型、知识库、引用及优化
LLM服务
知识图谱+向量搜索
文本答案
Kafka集群
Nebula Read
Nebula
AI应用
GPT3.5/GPT4
生成知识图谱及获取关键词摘要
AI生成填写信息点击生成按钮
网关层
开始
GPT
adj_kw2
PYTHON文本切割
提取关键词
添加、删除
AI应用逻辑
新上传文件
会话维度
文本块与关键词自动关联
费用明细记录
已有文件
按行拆分
待确认关键词展示
关键词提取并校准
通过询盘云权限获取对应权限的key
AI聊天点击发送按钮
Nebula Read
Redis集群
Hystrix熔断
1.关键词向量化2.知识图谱生成3.关键词总结4.文本块和关键词的自动关联
应用
目前不会存在文本块与关键词的关系
Other LLMs
关键词记录维护
1、对待校准关键词进行删除2、手段添加关键词
chunk3
embedding
消费花费记录
记录答案、关键词、引用文本的赞踩信息
结束
模型版本费用配置
记录余额
知识图谱
PY生成知识图谱
关键词校准
是否设置?
记录未采纳的关键词
询盘云增加菜单按钮控制权限
adj_kw1
此处应单独使用key进行权限的管理、不在使用id
redis
展示层
阶段放入
推送
企业维度:业务场景创建
生成答案
用户维度:业务场景应用
文件上传
vector1:chunk1
关键词与文本块的关系
删除
权限
否
运营后台增加余额+维护透支额度(充值)
组装prompt
Milvus
Redis
font color=\"#323232\
websocket
本次用户手动添加的词
前6条过LLM
产生一条初始记录(问题、业务员、类型)
文件详情查看
文件夹管理模块
搜索Q
余额减去预估费用之后未超过透支额度
处理完成
图谱检索
AI场景配置
资料文件
COS
图学习
文件(word、pdf)
查询配置
提示词填写
记录文本引用
文本向量化
关键词列表是持续增长的状态
存入关键词
提示词token数校验(1/8)
Answer
基于图学习
keyword1
用户手动维护
最终得到对应的key给前台
第一次被抽取出来的词
Milvus集群
生成进度条展示
记录手动添加手动关键词
提示词
基本信息
文件处理
依据key进行企业GPT的功能权限展示
记录关键词引用
预估费用方式:获取关键词:1、输入:60(聚类数量 文本块的1%,最多不超过60)* 10%的文本块数 * 300(文本块预估token)* 2 (两种聚类方式)2、输出:60(聚类数量 文本块的1%,最多不超过60)* 2(2种聚类方式)*10(每个聚类获取词的数量)*3(每个词的单词数)生成知识图谱:主要在于生成关键词描述的花费,固定i. 输入:1000(关键词)*12(文本块)*300(单个文本块 token 数) ii. 输出:1000(关键词)*1000(每个关键词描述的 token 数) iii. token 合计:3600000+1000000=4600000 iv. 金额合计:920 元
LLM
向量检索
chunk2
GPT3.5 (16k)按0.2元/1k tokens;GPT4 (8k)按1元/1k tokens向量化 0.05元/1K tokens
记录花费明细
调用知识库
AI生成逻辑
生成Prompt服务【核心服务】
问题向量化
NebulaGraph Studio
向量化按照模型的token比例收费
AI生成
代理层
NebulaGraph Dashboard
上次采纳确认使用的词
PY提取关键词
是
应用网关
上次使用关键词
NebulaGraph Database
透支余额校验
知识库管理
其他维护操作
默认启用状态,可编辑、删除
是否分步存储对应的记录数据
带有文件夹及标签条件
引用文本
用户在使用记录中,点击采纳\\已采纳
历史上已经被抽取过、添加过的词
文本块自动关联是图谱生成后直接取的文本块和关键词的关联关系
待补充
Chunks去重(15个向量检索+45个图谱检索文本)
2个
预估费用
图学习操作
会话列表(一个场景只能创建一个会话,支持删除会话,创建时间倒序)
用户对答案及引用点赞点踩
手动关联关键词
model:gpt3.5temp:标准
vector2:chunk2
已有的文本块
权限管理
知识图谱+向量搜索(超token处理)
余额未超过透支额度
用户
vector
问答(即文本块)
使用记录的存储
依据文本与关键词的记录
关键词与文本的关系维护记录
上次未采纳的关键词
Question
通知生成知识图谱
新关键词
检索知识库
GIT
PG主从
记录手动删除手动关键词
后续权限管理未定
keyword2
存储层
vector15:chunk15
本次抽取的应该结合历史一同处理完成进行展示
默认设置
点击生成知识图谱
弃用的关键词
模型
输出展示给用户
AI应用入口
用户手动新增关键词且不在所有关键词中存在过
询盘云配置权限角色
文本块
问答文件
socketnginx
consul集群
如果是关键词,需要额外记录关键词的赞踩数量
冗余字段维护
AI搜索
调用关系概要
默认设置:model:gpt3.5temp:标准
是否使用知识库
设置:知识库筛选(文件夹、标签)
通知提取关键词
文本拆分
AI搜索点击搜索按钮
执行知识管理生成知识图谱对应的流程
采纳的关键词
记录或删除采纳的数据
生成知识图谱前
token校验:1/8
文本块(继承文件标签,每条问答单独打标签)
自动关联关键词
AI搜索逻辑
用户维度
已经存在知识库处理关键词与文本块的关系
AI聊天
记录答案
adj_kw3
知识库所有文本块
知识图谱抽取出来的关键词
知识图谱获取关键词
文件删除
段落拆分