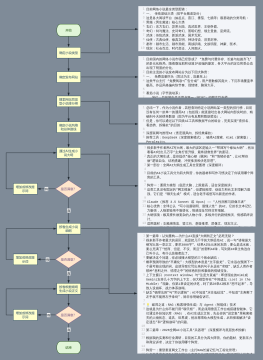
如何通过基座模型优化适应目标任务
需求背景:在特定行业里需要Ai助力
总结有哪些方式
Prompt Engineering
Retrieval Augmented Generation,RAG
这种方法将检索(或搜索)的能力集成到LLM文本生成中。它结合了一个检索系统和一个LLM,前者从大型语料库中获取相关文档片段,后者使用这些片段中的信息生成答案。本质上,RAG 帮助模型“查找”外部信息以改进其响应。
Fine-tuning
是采用预先训练的 LLM 并在较小的特定数据集上对其进行进一步训练的过程,以使其适应特定任务或提高其性能。通过微调,我们根据数据调整模型的权重,使其更适合我们应用程序的独特需求。
包括 Adapter Tuning、Prompt Tuning、Prefix Tuning、P-Tuning、P-Tuning v2 和 AdaLoRA。
Foundation Model
基于哪些指标来评判
准确性
实施复杂性
工作量
总拥有成本(TCO)
更新和扩展的便利性
准确度比较
提示工程(Prompt Engineering)的核心是在提供尽可能多的上下文信息的同时,通过提供少量示例(few-shot learning)来更好地让大模型了解您的用例。虽然结果在孤立情况下看起来令人印象深刻,但与本文中讨论的其他方法相比,它产生的结果最不准确。
检索增强生成(Retrieval Augmented Generation,RAG)的高质量结果是由于直接来自向量化信息存储的增强用例特定上下文。与 提示工程相比,它产生了大幅改善的结果,并且极低几率出现幻觉。
AI幻觉:回答违背基本常识,结果不准确
解决方向
访问实时信息
与搜索引擎集成
改进的训练数据
高级算法
微调(Fine-tuning)在准确性方面提供了相当高的结果,其输出质量与 RAG 相媲美。由于我们正在使用特定领域的数据更新模型权重,因此该模型能够产生更具上下文的回复。与 RAG 相比,质量可能会稍微好一些,这取决于使用情况。因此,评估是否真的值得花时间在两者之间进行权衡分析非常重要。通常选择微调的原因不仅仅是准确性,还包括数据变化频率、控制模型工件以符合监管、合规和可复现性等方面的考虑。
提供新的预训练数据集,从头开始训练可以产生最高质量的结果。由于模型是根据特定用例的数据进行训练,幻觉的可能性几乎为零,并且输出的准确性也是很高的。
子主题
实施复杂性
提示工程(Prompt Engineering)的实施复杂度相对较低,因为它几乎不需要编程。需要具备良好的英语(或其他人类解释)语言技能和领域专业知识,以制定一个带有上下文学习方法和少样本学习方法的良好提示。
检索增强生成(Retrieval Augmented Generation,RAG) 比提示工程更复杂,因为你需要具备编码和架构技能来实现这个解决方案。根据在 RAG 架构中选择的工具不同,复杂度可能会更高
微调(Fine-tuning)的复杂性甚至比提示工程和 RAG 还要高,因为模型的权重参数是通过调整脚本进行更改的,这需要数据科学和机器学习专业知识。
从头开始训练具有最高的实施复杂性,因为它需要大量的数据整理和处理,并且需要深入的数据科学和机器学习专业知识来训练一个相当大的 Foundation Model。
子主题
工作量
提示工程(Prompt Engineering)需要大量的反复努力才能做到完美。大语言模型对提示的用词比较敏感,有时候改变一个词甚至动词都会导致完全不同的回应。因此,为了让相应的大语言模型输出期望的结果,需要进行多次迭代才能做到准确无误
检索增强生成(Retrieval Augmented Generation,RAG) 还需要适度的努力,比提示工程稍微高一些,因为涉及到创建 Embeddings 和设置向量存储的任务。
微调(Fine-tuning)是一项比提示工程和 RAG 更费力的任务。虽然 Fine-tuning 可以使用很少的数据进行(在某些情况下甚至只需 30 个或更少的示例),但是设置 Fine-tuning 并正确获取可调参数值需要时间。
从头开始训练是所有方法中最费力的。它需要大量的迭代开发,以获得具有正确技术和业务结果的最佳模型。该过程始于收集和整理数据,设计模型架构,并尝试不同的建模方法,以找到适用于特定用例的最佳模型。这个过程可能非常漫长(几周到几个月),并且需要大量的计算资源。
子主题
总拥有成本(TCO)
提示工程(Prompt Engineering) 的成本可以非常低,因为您只需要维护提示工程模板,并在大模型版本更改或完全新的大模型出现时及时更新它们。除此之外,还会有一些通常与托管大模型或通过无服务器 API 使用它相关的费用。<br>
检索增强生成(Retrieval Augmented Generation,RAG) 的成本会比提示工程高一些,这是因为架构中涉及到多个组件。这将取决于使用的 Embedding 模型、向量存储和大模型。因此,它与提示工程相比成本更高,因为您需要支付三个不同的组件而不只是一个大模型。<br>
微调(Fine-tuning)的成本将高于 RAG 和提示工程,因为您正在调整一个需要强大计算能力、深度机器学习技能和对模型架构的理解的模型。特别是,由于每次基础模型版本更新或新批次数据进来时都需要进行调优,维护这样的解决方案的成本较高,并携带有关用例最新信息。<br>
从头开始训练的总体成本最高,因为团队需要负责整个数据处理和机器学习训练、调优和部署过程。这将需要一群高技能的机器学习专业人员来完成。由于需要频繁重新训练模型以使其与使用案例周围的新信息保持更新,因此维护这样的解决方案的成本非常高。
子主题
迭带扩展性
提示工程(Prompt Engineering) 具有非常高的灵活性,因为您只需要根据大模型和用例的变化来更改提示模板即可。<br>
检索增强生成(Retrieval Augmented Generation,RAG) 在架构变更方面具有最高的灵活性。您可以独立地改变 Embedding 模型、向量存储和 LLMs,对其他组件的影响很小到中等程度。它还具备在过程中添加更多组件(如复杂授权)而不影响其他组件的灵活性。<br>
微调(Fine-tuning)对于变化的适应性较低,因为任何数据和输入的更改都需要进行另一轮微调,这可能会非常复杂且耗时。此外,将同一个经过微调的模型适应到不同用例中也需要付出很大努力,因为相同的模型权重参数在其他领域上可能表现不佳。<br>
从头开始训练的灵活性最小。因为在这种情况下,模型是从头构建的,对模型进行更新会触发另一个重新训练周期。可以说,我们也可以对模型进行微调而不是从头重新训练,但准确性会有所变化。
子主题
总结
您希望在更改大模型和提示模板方面具有更高的灵活性,并且您的使用案例不包含大量领域上下文时,请使用提示工程(Prompt Engineering)。<br>
使用检索增强生成(Retrieval Augmented Generation,RAG)时,您可以在保持输出质量高的同时,获得最高程度的灵活性来更改不同组件(数据源、Embeddings、大模型、向量引擎)。<br>
使用微调(Fine-tuning)时,您可以更好地控制模型的构件和版本管理。当领域特定术语非常与数据相关(比如法律、生物学等)时,它也许会非常有用。<br>
如果以上方法都不适用于您,并且您有能力构建一个拥有数万亿个经过精心筛选的标记化数据样本、先进硬件基础设施和一支高技能机器学习专家团队,那么您可以从头开始训练一个基础大模型。当然,这需要相当昂贵的预算和时间成本来实现和落地应用。
材料来源
https://blog.csdn.net/qq_41929396/article/details/132689632
https://cloud.tencent.com/developer/article/2313660
大模型与智能体的交汇
重要智能体发布时间
• 3月21日,Camel 发布:通过角色扮演自主AI智能体来解决给定的任务<br>• 3月30日,AutoGPT 发布:根据任务设定自动地分阶段推进执行,并最终给出结果 • 4月3日,BabyAGI 发布:人工智能驱动的任务管理系统<br>• 4月7日, Smallville 西部小镇发布:斯坦福 25 个 AI 智能体相互交流<br>• 5月27日, Voyager发布:英伟达 AI 智能体自主写代码,游戏中全场景终身学习<br>• 8月1日,MetaGPT 发布: 实现多智能体通信,智能体也能轻松狼人杀<br>• 8月9日,OlaGPT 发布:首个模拟人类认知的思维框架<br>• 9月5日,ChatDev 发布:清华创建一个由多智能体协作运营的虚拟软件公司<br>• 9月29日,微软推出 AutoGen 框架,帮开发者创建基于大语言模型的复杂应用
LLM--->AGI
LLM 初期,对其能力边界还没有清晰认知,以为 LLM 是通向 AGI 的路径
LLM to AI Agent to AGI
AutoGPT和BabyAGI等项目为代表的大动作模型(Large-ActionModels/Large-AgentModels,<br>LAM )将 LLM 作为 Agent 的中心,将复杂任务进行分解,在每个子步骤实现自主决策和执行。
agent定义
给定特性的目标 AI Agent,Agent 能够自己创建任务、完成任务、创建新任务、重新确定任务列表的优先级、完成新的顶级任务,并循环直到达到目标。<br>
Agent 让 LLM 具备目标实现能力,并通过自我激励循环来实现给定的目标。即:Agent = LLM + Planning + Feedback + Tool use。
Agent 智能体与 Prompt 提示词的关系
AI Agent 绝大多数创新点还是在 Prompt 层面,即:通过更好的 Prompt 提示词来激发 LLM 模型的能力。通过 Prompt 提示词,让 LLM 大模型仿照 Prompt 给出的方式来执行的一种应用范式。<br>Prompt 里面包含关于 Tools 的描述,最后 AI Agent 智能体就可以根据模型的输出使用外部 Tools(例如计算器,搜索API,数据库,程序接口,各种模型的API) 能使用外部 API 或者知识库。<br>
子主题
子主题
关键组成
规划:一项复杂任务通常包括多个子步骤,Agent 需要提前将一项任务分解为多个子任务。<br>子目标与分解(Subgoal and decomposition):Agent 将复杂任务分解为更小、更易于处理的子目标,从而实现对复杂任务的高效处理。<br>反思与完善(Reflection and refinement):Agent 可以对历史的动作进行自我批评和自我反思,从错误中吸取教训,并为未来的步骤进行改进,从而提高最终结果的质量。<br><br>实现:通过prompt engine来引导 LLM 实现规划(即步骤分解)。<br>
任务分解
思维链(Chain-of-thought,CoT)一种改进的提示策略,用于提高 LLM 在复杂推理任务中的性能,如算术、常识和符号推理。CoT 已经成为增强复杂任务上模型性能的标准提示技术。<br>实现过程中,模型被指示「一步一步思考」,从而将困难任务分解为更小、更简单的步骤。在 AI Agent 中 CoT 将大型任务转化为多个可管理的小任务,并解释清楚模型的思维过程。
思维树(Tree of Thoughts,ToT),通过同时考虑多个可能的 Plan,并利用价值反馈机制进行决策,扩展了现有的规划方法。即通过每一步探索多种推理可能性来扩展 CoT。<br>首先将问题分解为多个思考步骤,并在每个步骤中生成多个思考,创建一种树结构。搜索过程可以是广度优先搜索(BFS)或深度优先搜索(DFS),其中每个状态由分类器或多数 vote 进行评估。具体任务分解过程可以通过以下三种方式完成:<br>基于 LLM 提示,如「XXX 的步骤是什么?」、「实现 XXX 的子目标是什么?」<br>使用特定于任务的提示,比如「写一个XXX故事大纲」<br>人工输入。
子主题
自我反省
react
思考(Thought):思考是由大模型创建的,为其行为和决定提供理论支撑。我们可以通过分析大模型的思考过程,来评估其即将采取的行动是否符合逻辑。它作为一个关键指标,能够帮助我们判断其决策的合理性。相比于人类的决策,Thought的存在赋予了大模型更出色的可解释性和可信度。
行动(Act):行动代表大模型认为需要采取的具体行为。行动一般由两个部分构成:动作和目标,这在编程中对应着API名称和其输入参数。大模型的一大优点在于,它可以根据思考的结果,选择合适的API并生成所需的参数。这确保了ReAct框架在执行方面的实用性。
观察(Obs):观察代表大模型如何获取外部输入。它就像大模型的感知系统,将环境的反馈信息同步给大模型,帮助它进一步进行分析或者决策。
ReAct 的扩展 Reflexion 框架
Reflexion 框架则为 Agent 配备了动态记忆和自我反思能力,提高 Reasoning 能力。通过借鉴 RL 流程,奖励模型提供简单的二元奖励,特定于任务的动作空间通过 LLM 进行增强,实现复杂推理步骤,动作空间遵循 ReAct 中的配置( Thought... Action ... Observation);在每个动作 a_t 之后,智能体计算启发式 h_t,并选择性地根据自我反思结果来决定重置环境,从而开始新的试验
子主题
Self-ask
Self-ask是一种follow-up的使用范式,仅仅包含 follow-up, immediate answer步骤,至于 follow-up多少个 step,完全由 Agent 自己决定。
两者比较
Chain-of-Thought 推理只是作为静态黑盒,它没有用外部知识,所以在推理过程中会出现事实幻想(fact hallucination)和错误传递(error propagation)的问题。<br>ReAct 克服了在思维链推理中的幻觉和错误传播问题,通过与简单的维基百科API交互,生成类似于人的任务解决型轨迹,解释性进一步增强。
短期记忆(Short-term memory):所有上下文学习(In-context Learning),都是利用模型的短期记忆来学习。<br>实现上主要利用 Prompt Engineering 。<br>长期记忆(Long-term memory):为 Agent 提供长时间保留和回忆信息的能力,这个时候需要借助外部向量存储和快速检索来实现<br>实现上,主要利用向量数据库。<br>
Agent 会调用外部提供好的 API,补充 LLM 输出中缺失的额外信息,包括当前状态信息、具体的代码执行能力、访问专有信息源等,都需要借助外部的工具组件。<br>