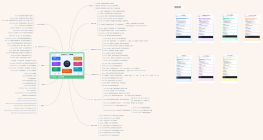
使用目标
统一团队语言:让前端团队快速理解 AI 全栈核心概念
建立概念关系:模型、数据、工具、评估、安全、部署如何串起来
形成学习边界:两周目标是交付 AI 应用 PoC/MVP,不是从零训练模型
一、基础认知层
AI / 人工智能:让机器表现出理解、生成、推理、决策等智能行为的技术集合
ML / 机器学习:让系统从数据中学习规律,而不是完全靠人写规则
Deep Learning / 深度学习:使用多层神经网络学习复杂模式的机器学习方法
Generative AI / 生成式 AI:能生成文本、图片、音频、代码等内容的 AI
Foundation Model / 基座模型:在大规模数据上训练出的通用模型,可适配多种任务
LLM / 大语言模型:擅长理解和生成自然语言、代码、结构化数据的模型
工程理解:LLM 是语言与推理引擎,不是企业知识库
使用边界:需要结合 RAG、Tool Calling、Eval 和 Guardrails
Transformer:当前很多 LLM 的核心模型架构,Day 1 只需知道它是底层架构
Token:模型处理文本的基本单位,影响成本、上下文长度、流式输出和文档切分
Context Window / 上下文窗口:模型一次请求能看见的最大 token 范围
Hallucination / 幻觉:模型生成看似合理但不真实或无依据的内容
二、模型调用与 Prompt 层
Model API / 模型 API:通过 HTTP 或 SDK 调用大模型能力的接口
Prompt / 提示词:给模型的任务指令、上下文、输出要求和示例
工程建议:Prompt 是工程资产,需要版本化、测试和评估
System Prompt / 系统提示词:约束模型角色、边界和行为的高优先级指令
User Prompt / 用户提示词:用户本轮输入,需要清洗、截断、权限检查和上下文拼装
Few-shot Prompting:给模型几个输入输出示例,引导它按样例完成任务
Temperature:控制输出随机性,越低越稳定,越高越发散
Top-p:控制候选 token 采样范围,影响生成发散程度
Streaming / 流式输出:模型边生成边返回结果,是聊天体验的基础能力
Structured Output / 结构化输出:让模型输出符合 schema 的 JSON 等结构
JSON Schema:描述 JSON 字段类型和约束,用于减少输出格式漂移
三、知识增强与 RAG 层
Vector / 向量:一组数字,用于表示文本或图片的语义特征
Embedding / 嵌入:把文本、图片等内容转成向量的过程
Chunking / 文档切分:把长文档切成较小片段
注意:chunk 太大浪费上下文,chunk 太小容易丢语义
Vector Database / 向量库:存储向量并支持相似度检索的数据库
常见选择:pgvector、Weaviate、Pinecone、Milvus
Retriever / 检索器:根据用户问题从知识库中找相关内容的组件
RAG / 检索增强生成:先检索资料,再让模型基于资料回答
典型流程:文档解析 -> 切分 -> 向量化 -> 入库 -> 检索 -> 拼上下文 -> 生成回答 -> 引用 -> 评估
Rerank / 重排:对初步检索结果重新排序,提高上下文质量
Citation / 引用:回答中附带来源文档、段落、页码或 URL
Grounding / 事实锚定:让回答尽量基于给定资料,而不是自由发挥
Refusal / 拒答:资料不足或高风险时明确不回答
四、Tool、Agent 与 MCP 层
Tool Calling / 工具调用:让模型决定调用哪个工具以及传什么参数
Function Calling / 函数调用:Tool Calling 的常见实现形式
Tool / 工具:模型可请求使用的外部能力,例如查订单、查工单、查知识库
Workflow / 工作流:由程序固定控制步骤的任务流程
适合:规则明确、路径固定、需要强可控的任务
Agent / 智能体:能围绕目标多步调用模型、工具和状态完成任务的系统
组成:模型、指令、工具、状态、护栏、编排、评估
建议:两周冲刺先掌握单 Agent,不急着做多 Agent
Memory / 记忆:保存短期或长期上下文的机制
注意:不能什么都记,要考虑隐私、过期、错误记忆和权限
Human-in-the-loop / 人工介入:高风险或不确定任务中让人确认
MCP / Model Context Protocol:标准化连接工具、资源和提示模板的协议
MCP Tool:MCP server 暴露给模型可调用的动作
MCP Resource:MCP server 暴露的可读取上下文数据
MCP Prompt:MCP server 暴露的可复用提示模板
五、框架与工具层
AI SDK:Vercel 提供的 TypeScript AI 应用开发工具包,适合前端团队
LangChain:构建 LLM 应用、RAG、Agent、工具链的框架
LangGraph:构建可控 Agent / 多步工作流的框架
LlamaIndex:偏数据索引、RAG、知识库应用的框架
Ollama:本地运行大模型的工具,适合本地模型和本地 RAG Demo
Dify:开源 LLM 应用开发平台,适合快速搭知识库和工作流原型
Coze / 扣子:智能体与工作流平台,适合低代码快速验证 Agent 场景
FastGPT:知识库问答和工作流平台,常用于 RAG 快速落地
n8n:自动化工作流工具,可与 AI 工具结合做业务自动化
六、评估与可观测性层
Eval / 评估:用测试集和评分标准衡量 AI 输出质量
Eval Dataset / 评估集:一组固定测试问题、期望行为和评分规则
Rubric / 评分规则:判断回答好坏的打分标准,例如正确性、忠实性、引用质量、安全性
LLM-as-a-judge:用另一个模型按规则给输出打分,需要人工校准
Trace:一次 AI 请求或 Agent 执行过程的完整记录
Observability / 可观测性:日志、trace、指标、成本等监控能力
Prompt Versioning:记录 Prompt 的版本、变更和效果
Regression Test / 回归测试:改 Prompt、模型或 RAG 后复跑评估集
七、安全、治理与生产化层
Guardrails / 护栏:输入、输出、工具、权限、格式等安全控制
Prompt Injection / Prompt 注入:恶意输入诱导模型忽略规则或泄露信息
RBAC / ACL:控制谁能访问哪些数据和工具,RAG 检索也必须做权限过滤
Rate Limit / 限流:限制请求频率和调用次数,控制成本和防止滥用
Cost Control / 成本控制:管理 token、模型、向量库、日志等成本
Audit Log / 审计日志:记录用户、工具、敏感操作和结果
Fallback / 回退机制:主模型、工具或解析失败时切换备用方案
Cache / 缓存:缓存模型或检索结果,减少重复调用,但要注意数据过期
Model Gateway / 模型网关:对多模型供应商做统一封装
Gray Release / 灰度发布:小范围上线验证效果,便于回滚
八、关键关系
LLM 与知识库:LLM 不是企业知识库,企业知识要通过 RAG 或工具接入
RAG 与 Agent:RAG 负责找资料,Agent 负责围绕目标动态选择步骤和工具
Tool Calling 与 MCP:Tool Calling 是调用模式,MCP 是工具/资源暴露协议
Prompt 与 Guardrails:Prompt 能约束行为,但不能替代权限、审计和安全护栏
Eval 与上线:没有 eval,就很难证明模型、Prompt 或 RAG 改动真的变好
九、 自测题
LLM 是什么?它为什么不是数据库?
Token 为什么会影响成本和上下文长度?
RAG 的完整流程是什么?
Embedding 和向量库分别解决什么问题?
Tool Calling 和普通模型问答有什么区别?
Agent 和 Workflow 的区别是什么?
MCP 的 tools、resources、prompts 分别是什么?
为什么 AI 应用必须做 Eval?
Prompt Injection 是什么?为什么 Prompt 本身不是安全边界?
两周冲刺里为什么不建议把微调作为主线?
十、推荐资料
OpenAI Docs:https://platform.openai.com/docs
Vercel AI SDK:https://ai-sdk.dev/docs/introduction
LangChain JS Docs:https://docs.langchain.com/oss/javascript/langchain/overview
Model Context Protocol:https://modelcontextprotocol.io/
Hugging Face LLM Course:https://huggingface.co/course
Pinecone RAG Guide:https://www.pinecone.io/learn/retrieval-augmented-generation/
Phoenix Evals:https://arize.com/docs/phoenix/evaluation/llm-evals