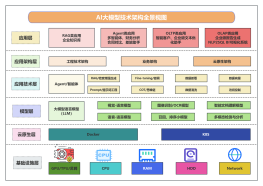
大语言模型LLaMa训练流程图
2023-12-13 10:23:40 0 举报详细解释了大语言模型训练过程
模板推荐
作者其他创作
大纲/内容





Collect
Collect

Collect

Collect
0 条评论
下一页