走进AI(二) | 机器如何学习?
2024-01-04 16:11:40 0 举报AI智能生成
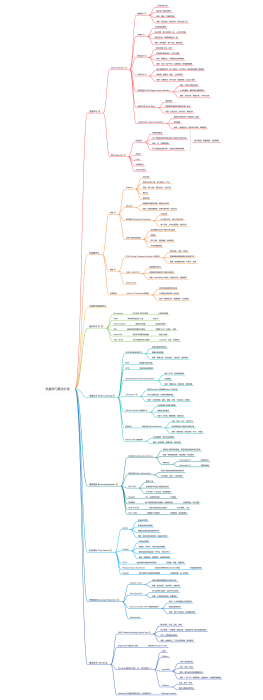
机器如何学习?
模板推荐
作者其他创作
大纲/内容








0 条评论
下一页

