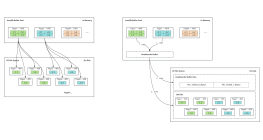
Redo logBuffer
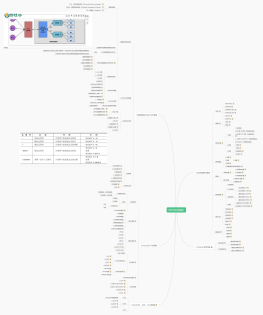
索引优化MYISAM->非聚簇,数据文件与索引文件分开存放1.文件结构: MYD、MYI、frm2.叶子节点:data -> 指针span style=\"font-size: inherit;\
memory
1.undo日志版本链与read view机制2.用两个隐藏字段trx_id和roll_pointer把这些undo日志串联起来形成一个历史记录版本链MVCC机制的实现就是通过read-view机制与undo版本链比对机制,使得不同的事务会根据数据版本链对比规则读取同一条数据在版本链上的不同版本数据。
77
读写磁盘,数据结构存储的实现
undo日志文件Innodb特有name=xx
data
连接器
redo日志文件innodb特有name = yy
30
Mysql
B-Tree特性1.叶节点具有相同的深度,叶子节点的指针为空2.所有索引元素不重复3.节点中的数据索引从左到右递增排序
客户端
执行器
binlog文件
myisam
sort相关排序方式支持:1.index:扫描索引本身完成排序,最左前缀,排序字段在索引列2.filesort:效率低,排序字段不在索引列能用覆盖索引就用覆盖索引,trace工具查看排序方式 -> sort_mode:rowid 双路排序max_length_for_sort_data 单路排序:一次性取出满足条件行的所有字段,在sort buffer中进行排序双路排序:先根据相应的条件取出相应的排序字段和行ID字段总长度 < max_length_for_sort_data(1024B) -> 单路字段总长度 > max_length_for_sort_data(1024B) -> 双路
调用引擎接口
... ...
执行计划生产索引选择
id
select * from t1 join t2 on t1.id=t2.id where t1.name='xx' and t2.name='yy';两种执行方案:1.取t1.name='xx',然后根据id查找t2.name='yy'的数据2.取t2.name='yy',然后根据id查找t1.name='xx'的数据
磁盘文件(ibd)
2.写入更新数据的旧值便于回滚
调用引擎接口获取查询结果
15
upstream轮询、权重、ip_hash、最少连接serverlocation listen 监听端口 server_name 访问域名
如果事务提交成功,buff pool中的数据没写入磁盘,可以用redo日志数据恢复buff poo的缓存数据
49
管理连接与权限校验
4.写入redo日志
22
缓存总结:二级缓存 QCache:32M,单个查询1Mjoin buffer:256ksort buffer:1Mbinlog:数据恢复InnoDb引擎buffer pool、Redo log bufferundolog
select_type
possible_keys
表关联相关嵌套循环连接(Nested-Loop join)算法 -> NLJextra:Using join buffer inner join:小表是驱动表,大表是被驱动表 left join:左表驱动表,右表被驱动表EXPLAIN select * from t1 inner join t2 on t1.a= t2.a; 1.取被驱动表的每一行数据(过滤后的数据)(整行数据) 2.取关联字段 到驱动表中对比 3.满足的结果行合并NLJ 如果被驱动表无索引,效率低下基于块的嵌套循环(Block Nested-Loop join)连接算法 -> BNLextra:Using join buffer (Block Nested Loop)join_buffer_size:256kb(默认大小) -> 分段扫描1. 把 t2 的所有数据放入到 join_buffer 中2. 把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比3. 返回满足 join 条件的数据
rows
innodb
词法分析器
6.准备提交事务,binlog写入磁盘
page...
这块JB流程画着太复杂,看心情后续补充。。。
数据页大小:16384 16*1024 16kbshow global status like 'Innodb_page_size';关闭mysql5.7新特性对衍生表的合并优化set session optimizer_switch='derived_merge=off';#还原默认配置set session optimizer_switch='derived_merge=on';查看binlog开启show variables like '%log_bin%';查看binlog内容/usr/local/mysql/bin/mysqlbinlog设置事务隔离级别set tx_isolation='REPEATABLE-READ';
8.随机写入磁盘以page为单位写入后磁盘name=yy
18
20
Explain详解:id:执行优先级,越大优先级越高,id相同,排在前面的优先执行select_type: simple:简单查询,不包含子查询与union primary:复杂查询中最外层的select subquery:包含在select中的子查询,不在from子句中 derived:包含在from子句的子查询,子查询的结果集放在临时表中(派生表)table:表名partitions:分区type:关联类型:system>const>eq_ref>ref>range>index>all eq_ref:主键索引 ref:二级索引 range:常用于in、>、<、between、>= index:通常扫描二级索引的叶子节点全索引,覆盖索引,二级索引比较小 all:通常是聚簇索引的叶子节点,扫描的数据比较大possible_keys:可能用到的索引key:索引字段key_len:索引的大小row:总行数filtered:extra: Using index:使用覆盖索引 Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖 Using index condition:查询的列不完全被索引覆盖,where中有范围条件; Using filesort:将用外部排序而不是索引排序,数据量较小时用内存排序, 否则需要在磁盘完成排序。需要考虑使用索引来优化
数据恢复:binLog1.配置binLog,2.binlog的三种格式: statement:每一条会修改数据的sql都会记录在binlog中 row:不记录sql语句上下文信息,仅保存哪天记录被修改 mixed:statement与row的混合体InnoDB与MYISAM区别InnoDB支持事务(TRANSACTION)InnoDB支持行级锁font color=\"#e74f4c\
... ...
partitions
pagename=xx
type
3.更新内存数据
1.加载缓存数据:id=xx的记录所在的整页数据
filtered
查询缓存
key_len
key
Nginx
5.准备提交事务redo日志写入磁盘
Extra
table
词法分析,语法分析
修改的数据
... ...
第一范式(1NF):每个列都不可以再拆分。第二范式(2NF):在第一范式的基础上,非主键列完全依赖于主键, 而不能是依赖于主键的一部分。第三范式(3NF):在第二范式的基础上,非主键列只依赖于主键, 不依赖于其他非主键。
ref
引擎层
5.8版本之后取消k:查询语句v:结果集SQL_CACHE
50
server
56
IO线程
B+Tree特性1.非叶子节点不存储数据,只存储索引2.叶子节点包含所有的索引字段3.叶子节点用指针连接,提高区间访问性能
pagename=yy
7.写入commit标记到redolog日志文件中提交事务完成,该标记保证事务提交后,redo与binlog数据一致
MVCC实现
事务四大特性:原子性,隔离性,一致性,持久性脏读:事务A读取到了事务B已经修改但尚未提交的数据不可重复读:事务A相同查询语句在不同时刻,获取结果不一致幻读:事务A读取到了事务B提交的新增数据隔离级别:读未提交,读已提交,可重复读,串行化
如果事务提交失败要回滚数据,可以用undo日志恢复
优化器
Buffer Pool缓存池