GBDT模型学习
2024-07-09 13:47:38 7 举报AI智能生成
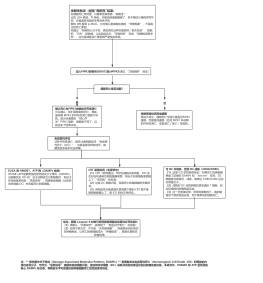
GBDT(Gradient Boosting Decision Tree)模型是一种基于决策树算法的集成学习方法,主要用于回归和分类任务。GBDT模型通过迭代地训练决策树,然后将所有树的预测结果相加得到最终的预测结果。在每次迭代中,新的决策树会尝试纠正之前树的预测错误,从而提升整体的预测性能。GBDT模型的特点包括:鲁棒性强,可以处理非线性数据和特征之间的相互作用,以及可以自动进行特征选择和降维。GBDT模型的训练过程包括:初始化一个常数值作为预测结果,然后迭代地对每个训练样本进行预测,并计算损失函数,最后使用梯度提升算法训练决策树,以最小化损失函数。GBDT模型在许多领域都有广泛的应用,如广告点击率预测、信用评分、疾病预测等。
模板推荐
作者其他创作
大纲/内容




0 条评论
下一页

