RDB和AOF
RDB 内存快照
就是 Redis 内存中的数据在某一刻的状态数据。
快照执行策略
bgsave
fork产生一个子进程用于写入 RDB 文件,快照持久化完全交给子进程来处理,父进程继续处理客户端请求,生成 RDB 文件的默认配置
写时复制
bgsave 子进程可以共享主线程的所有内存数据,读取主线程的数据并写入到 RDB 文件。
优缺点
采用二进制 + 数据压缩的方式写磁盘,文件体积小,快照的恢复速度快,
文件频率不好把握,频率过低宕机丢失的数据就会比较多;太快,又会消耗额外开销
AOF 写后日志
Redis 服务器的顺序指令序列,AOF 日志只记录对内存进行修改的指令记录。
写回磁盘策略
fsync/fdatasync 同步写入,数据不会修
appendfsync
always:同步写回
everysec:每秒写回
no:操作系统控制,
优缺点
记录redis写指令,不会丢数据
数据恢复需要重放指令,恢复较慢
AOF日志重写机制
指令:bgrewriteaof
原理就是开辟一个子进程对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。序列化完毕后再将操作期间发生的增量 AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了
AOF 重写也有一个重写日志,为什么它不共享使用 AOF 本身的日志呢?
一个原因是父子进程写同一个文件必然会产生竞争问题,控制竞争就意味着会影响父进程的性能。
如果 AOF 重写过程中失败了,那么原本的 AOF 文件相当于被污染了,无法做恢复使用
Redis 4.0以后混合日志模型
将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。
Redis Replication主从原理
数据同步原理
第一次主从全力同步
连接建立
从库配置主库的ip和端口
从库执行 replicaof 并发送 psync 命令,表示要执行数据同步
主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。
主库数据同步到从库
master 执行 bgsave命令生成 RDB 文件,并将文件发送给从库
同时主库为每一个 slave 开辟一块 replication buffer 缓冲区记录从生成 RDB 文件开始收到的所有写命令
从库收到 RDB 文件后保存到磁盘,并清空当前数据库的数据,再加载 RDB 文件数据到内存中。
发送同步期间新写命令到从库
从节点加载 RDB 完成后,主节点将 replication buffer 缓冲区的数据发送到从节点,Slave 接收并执行,从节点同步至主节点相同的状态。
replication buffer(master 端上创建的缓冲区)
存放哪些时间端数据
master 执行 bgsave 产生 RDB 的期间的写操作
master 发送 rdb 到 slave 网络传输期间的写操作;
slave load rdb 文件把数据恢复到内存的期间的写操作。
replication buffer 太小会引发的问题
太小会导致主从复制连接断开。
主从复制连接断开,导致主从上出现重新执行 bgsave 和 rdb 重传操作无限循环。
为什么使用RDB。不是AOF?
二进制文件,网络传输和磁盘写入效率高
从库进行数据恢复的时候,RDB 的恢复效率也要高于 AOF
主从运行期间的同步
基于长连接的命令传播
命令传播阶段,除了发送写命令,主从节点还维持着心跳机制:PING 和 REPLCONF ACK。
主->从:PING,判断从节点是否超市
从->主:REPLCONF ACK
检测主从服务器的网络连接状态
辅助实现 min-slaves 选项。
主从库网络断开重连
Redis 2.8 之前采用全量复制,2.8以后采增量复制
增量复制:用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效
repl_backlog_buffer 缓冲区
repl_backlog_buffer 是一个定长的环形数组,如果数组内容满了,就会从头开始覆盖前面的内容。
master 使用 master_repl_offset记录自己写到的位置偏移量,slave 则使用 slave_repl_offset记录已经读取到的偏移量。
增量复制的流程
slave 会先发送 psync 命令给 master,同时将自己的 runID,slave_repl_offset发送给 master。
master 只需要把 master_repl_offset与 slave_repl_offset之间的命令同步给从库即可。
repl_backlog_buffer 太小的话从库还没读取到就被 Master 的新写操作覆盖了?
一旦被覆盖就会执行全量复制
调整repl_backlog_size
计算公式:repl_backlog_buffer = 2*second * write_size_per_second
second:从服务器断开重连主服务器所需的平均时间
write_size_per_second:master 平均每秒产生的命令数据量大小
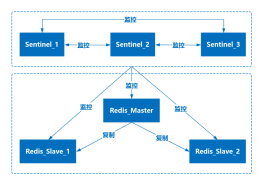
哨兵原理
哨兵是 Redis 的一种运行模式,它专注于对 Redis 实例(主节点、从节点)运行状态的监控,并能够在主节点发生故障时通过一系列的机制实现选主及主从切换,实现故障转移,确保整个 Redis 系统的可用性
功能
监控:持续监控 master 、slave 是否处于预期工作状态。
主观下线 sdown
如果哨兵ping redis节点,redis未响应,且redis节点是 slave节点。就标记为 sdown
客观下线 odown
如果哨兵集群ping redis节点,redis未响应,且redis节点是 master节点。过半的哨兵(Quorum配置)都任务master节挂了,就会标记为odown
自动切换主库:当 Master 运行故障,哨兵启动自动故障恢复流程:从 slave 中选择一台作为新 master
redis实例是正常运行的,且主从间网络是正常的
slave 优先级,通过 slave-priority 配置项,
slave_repl_offset与 master_repl_offset进度差距
slave runID,在优先级和复制进度都相同的情况下,ID 号最小的从库得分最高,
通知:让 slave 执行 replicaof ,与新的 master 同步;并且通知客户端与新 master 建立连接。
工作原理
哨兵间的集群通信
Redis 的 pub/sub 发布/订阅机制。
master 有一个 __sentinel__:hello 的专用通道,用于哨兵之间发布和订阅消息。
哨兵和salve节点间通信
Info命令,从master获取salve节点
哨兵和客户端通信
Redis 的 pub/sub 发布/订阅机制。
Redis Cluster
Redis 集群是一种分布式数据库方案,集群通过分片(sharding)来进行数据管理(「分治思想」的一种实践),并提供复制和故障转移功能。集群间 通过Gossip协议相互交互集群信息
将数据划分为 16384 的 slots,每个节点负责一部分槽位。槽位的信息存储于每个节点中。
Key 与哈希槽映射过程可以分为两大步骤
据键值对的 key,使用 CRC16 算法,计算出一个 16 bit 的值;
16 bit 的值对 16384 执行取模,得到 0 ~ 16383 的数表示 key 对应的哈希槽。
Cluster 还允许用户强制某个 key 挂在特定槽位上,可以通过键入tag标记
故障检测
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变
故障转移
当一个 Slave 发现自己的主节点进入已下线状态后,从节点将开始对下线的主节点进行故障转移。
从下线的 Master 及节点的 Slave 节点列表选择一个节点成为新主节点。
新主节点会撤销所有对已下线主节点的 slot 指派,并将这些 slots 指派给自己。
新的主节点向集群广播一条 PONG 消息,这条 PONG 消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点,并且这个主节点已经接管了原本由已下线节点负责处理的槽。
新的主节点开始接收处理槽有关的命令请求,故障转移完成。
选主流程
集群的配置纪元 +1,是一个自增计数器,初始值 0 ,每次执行故障转移都会 +1
检测到主节点下线的从节点向集群广播一条CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,要求所有收到这条消息、并且具有投票权的主节点向这个从节点投票。
这个主节点尚未投票给其他从节点,那么主节点将向要求投票的从节点返回一条CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示这个主节点支持从节点成为新的主节点。
参与选举的从节点都会接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,如果收集到的票 >= (N/2) + 1 支持,那么这个从节点就被选举为新主节点。
如果在一个配置纪元里面没有从节点能收集到足够多的支持票,那么集群进入一个新的配置纪元,并再次进行选举,直到选出新的主节点为止。
客户端怎么确定访问的数据到底分布在哪个实例上?
Redis 实例会将自己的哈希槽信息通过 Gossip 协议发送给集群中其他的实例,每个实例都有hash槽和实例之间的映射关系
客户端连接集群中的redis实例,通过将 key 通过 CRC16 计算出一个值再对 16384 取模得到对应的 Slot,
定位到槽以后还需要进一步定位到该 Slot 所在 Redis 实例
哈希槽与实例之间的映射关系由于新增实例或者负载均衡重新分配导致改变?
Redis Cluster 提供了重定向机制
MOVED 错误(负载均衡,数据已经迁移到其他实例上)
ASK 错误:slot槽正常迁移,