AI学习路线图
2025-05-26 15:54:53 1 举报AI智能生成
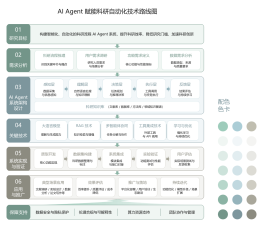
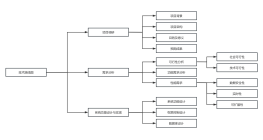
系统地规划了AI学习的关键阶段,涵盖从数学基础到深度学习模型的核心内容
模板推荐
作者其他创作
大纲/内容




Collect
Collect

Collect

Collect
0 条评论
下一页

