AI大模型应用&工程化路线图
2025-10-21 22:55:58 2 举报AI智能生成
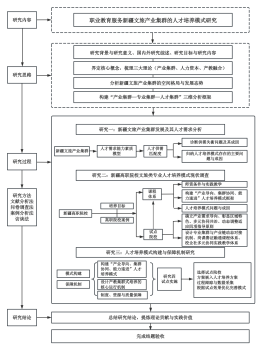
《AI大模型应用&工程化路线图》详细阐述了人工智能领域在大模型研发方面的关键应用与实际操作指南。
模板推荐
作者其他创作
大纲/内容





Collect

Collect

Collect
Collect
0 条评论
下一页

