大模型的分类维度
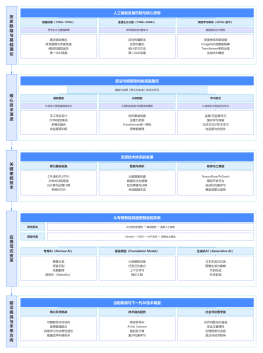
按模型规模与参数数量划分
小模型
中型模型
大型模型
超大型模型
按技术架构与模型类型划分
Transformer 架构模型:目前主流大模型均基于 Transformer 架构(自注意力机制),如 GPT 系列(decoder-only)、BERT(encoder-only)、T5(encoder-decoder)。特点:通过自注意力机制捕捉文本长距离依赖关系,是自然语言处理(NLP)大模型的 “标准架构”
多模态模型:支持处理文本、图像、音频、视频等多种模态数据,如 GPT-4V、Gemini、文心一言(多模态版)、Midjourney(文本生成图像)。特点:突破单文本限制,可实现 “图文理解”“音视频分析” 等跨模态任务,应用场景更广泛。
专用架构模型:针对特定任务优化的架构,如 MoE(混合专家模型,如 GPT-4、DeepMind GLaM)、稀疏激活模型。特点:通过 “激活部分参数” 提升效率,在保持大模型能力的同时降低计算成本。
按训练目标与能力定位划分
通用大模型:以 “全领域通用能力” 为目标,可处理文本生成、问答、翻译、代码等多种任务,如 GPT-3/4、豆包、智谱清言、Kimi。特点:适用场景广泛,无需针对单一任务深度优化,主打 “一站式解决多种需求”。
垂直领域大模型:针对特定行业或任务训练,聚焦某一领域的专业能力,如医疗大模型(如医疗问诊)、法律大模型(如北大法宝、律舟大模型)、代码大模型(如 CodeLlama、DeepSeek-Coder)。特点:在垂直领域的知识深度、准确性远超通用模型,需结合领域数据微调,解决专业场景问题(如医疗诊断、合同分析)。
任务专用模型:针对单一任务优化,如摘要生成模型(如 BART)、情感分析模型(如 DistilBERT 微调版)、图像生成模型(如 Stable Diffusion)。特点:在特定任务上效率更高、效果更佳,但通用性极差。<br>
按部署方式与访问形式划分
云端大模型:部署在云端服务器,用户通过 API 接口访问(如 OpenAI 的 GPT 系列、Anthropic 的 Claude、文心一言 API)。特点:依赖云端算力,用户无需本地硬件资源,但受网络稳定性和服务商限制,数据隐私依赖第三方保障。
开源大模型:模型权重开源,允许用户本地部署、修改和二次训练,如 LLaMA 系列、Mistral、Qwen(通义千问开源版)。特点:灵活性高,可本地化部署(保障数据隐私),但对用户硬件资源和技术能力有要求。
轻量化 / 边缘大模型:通过模型压缩(如量化、剪枝)适配边缘设备(如手机、物联网设备),如 GPT-4 量化版、华为盘古边缘版。特点:低延迟、低功耗,适合离线场景,但能力通常弱于完整版模型。<br>
按训练数据与知识覆盖划分
通用知识模型:训练数据涵盖书籍、网页、论文、新闻等通用领域内容,知识覆盖广泛但深度有限,如 ChatGPT、豆包。
专业知识模型:训练数据以某一专业领域的文献、数据为主(如医学论文、法律条文、工程手册),如 PubMedGPT(医疗)、LawGPT(法律)。
实时知识模型:支持接入实时数据(如联网搜索、数据库更新),可获取最新信息,如 New Bing(结合搜索引擎)、Kimi(支持实时联网)。特点:解决传统大模型 “知识滞后” 问题,能响应最新事件或动态
按技术归属与研发主体划分
巨头自研模型:由科技巨头研发,依托雄厚资源和技术积累,如 OpenAI(GPT 系列)、谷歌(Gemini)、微软(Azure OpenAI)、百度(文心一言)。
创业公司模型:由 AI 创业公司研发,聚焦特定技术或场景,如 Anthropic(Claude)、DeepSeek(深度求索)、智谱 AI(智谱清言)。
<br>
学术机构模型:由高校或科研机构研发,侧重技术探索,如斯坦福大学(Alpaca)、清华大学(ChatGLM)。
地域划分:国产大模型(豆包)、国外大模型(GPT )。