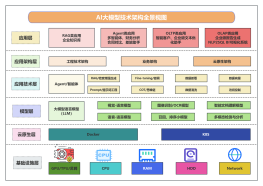
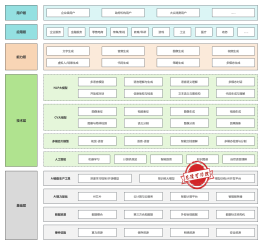
大语言模型教学任务
Transformer基础架构与模型分类 1.pptx
学习目的:理解Transformer核心组件(编码器与解码器)的基本原理,掌握三种主流大语言模型架构的分类依据与核心区别。
学习内容:Transformer模型的编码器-解码器基础结构;Encoder-Only、Decoder-Only、Encoder-Decoder三种架构的技术路线与应用场景差异。
学习要求:能够比较三种架构,并理解不同任务的代表性模型。
编码器专用模型(Encoder-Only)与BERT
学习目的:掌握Encoder-Only模型的设计哲学与训练机制,理解掩码语言建模技术,熟悉句子分类、Token标注等典型任务。
学习内容:Encoder-Only模型的表征学习特性;掩码训练技术细节;BERT在单句分类、序列标注、问答系统中的具体应用方式。
学习要求:能够解释掩码语言模型训练流程。
解码器专用模型(Decoder-Only)与GPT系列模型
学习目的:理解Decoder-Only模型的自回归生成机制,掌握GPT-1到GPT-3的技术演进逻辑及Zero-shot/Few-shot学习范式。
学习内容:GPT系列三代模型的参数规模、核心创新(预训练+微调→Zero-shot→In-context learning);自回归生成原理与提示工程概念。
学习要求:能够理解GPT-1/2/3的架构差异与迁移学习策略。
大模型预训练技术体系
预训练基础与数据工程
学习目的:理解大模型预训练的核心概念与数据重要性,掌握通用数据与专业数据的获取策略及预处理方法,建立对"数据质量决定模型性能"的根本认知。
学习内容:大模型预训练的基本原理与GIGO原则;通用数据源(网页、书籍、对话)与专业数据源(科学论文、代码)的代表性语料库;数据规模与质量对模型性能的双重影响机制。
学习要求:能够区分不同数据源的适用场景,列举至少3个主流预训练语料库;理解数据预处理策略对训练稳定性的作用;具备评估数据质量的基础判断力。
训练任务与参数优化
学习目的:掌握语言建模和去噪自编码两大核心预训练任务,精通批量大小、学习率调度与优化器配置策略,理解大规模模型训练中的稳定性挑战与应对方案。
学习内容:Next-token prediction与DAE任务的技术实现差异;动态批量调整、Warm-up衰减学习率策略;AdamW优化器原理;损失突变检测与检查点回滚稳定机制。
学习要求:能够配置AdamW优化器参数并设计学习率调度曲线;理解损失突变的成因与重启训练策略;具备根据硬件条件调整批量大小的实践能力。
硬件架构与高效训练技术
学习目的:理解CPU/GPU架构差异对深度学习的影响,掌握混合精度训练与ZeRO系列内存优化技术,能够在显存受限条件下实现超大规模模型训练。
学习内容:GPU并行计算核心优势与CPU控制单元的本质区别;FP16/BF16/TF32混合精度训练原理与数值稳定性;ZeRO-1/2/3的分布式存储机制与内存优化梯度。
学习要求:能够根据模型规模选择合适的数据精度格式;理解ZeRO技术的内存节省原理并配置训练框架;具备在有限显存下估算最大可训练模型参数量的能力。
大模型微调实战
指令微调基础与数据集构造
学习目的:理解大模型从预训练到微调的逻辑,掌握指令微调数据集的设计规范与构建方法
学习内容:系统学习指令微调的核心概念及其与预训练任务的本质区别,理解InstructGPT提出的10类典型指令结构掌握指令数据集的输入-输出对设计规范与任务适配。
学习要求:能够独立完成单轮与多轮指令数据实例的设计,理解不同任务类型对应的指令模板差异。
对齐优化与高效微调算法
学习目的:理解大模型与人类价值观对齐的技术,LoRA等参数高效微调算法的原理与实现,提升模型训练效率。
学习内容:介绍RLHF算法的三阶段流程(奖励模型训练、策略优化、人类反馈迭代),理解对齐原则;学习LoRA的低秩分解机制、缩放系数配置策略等。
学习要求:能够进行RLHF的完整工作流程并应用到具体场景中;掌握LoRA关键参数设置(秩r、缩放系数α、Dropout率),具备根据模型规模调整配置的能力。
微调工具链与多模态实践
学习目的:掌握工业级微调工具的使用方法,理解图文多模态指令微调的实现机制,了解熟悉跨模态数据整合与模型优化的实践能力。
学习内容:熟悉LLaMA-Factory等集成工具的数据-模型映射流程;学习多模态指令遵循数据的构成,掌握图文对齐数据格式与批处理。
学习要求:能够独立完成工具链环境配置与端到端微调流程;准确构建图像-文本-标签三元组数据,并理解多模态指令微调的评估指标与迭代优化方法。
模型微调(Fine-tuning):3.pptx
大模型评估
学习目的:掌握大模型在指令微调、RLHF对齐、LoRA适配及多模态扩展后的系统性评估方法,建立量化验证能力,确保模型输出符合预期任务目标。
学习内容:学习传统NLP指标(BLEU/ROUGE)与指令遵循准确率测评,掌握基于奖励模型的评估(A/B测试、Elo评分);理解LoRA等参数高效方法的显存/速度对比评估框架。
学习要求:能够独立设计端到端评估方案,运用MMLU、HumanEval等基准测试集完成评测。
推理模型
推理模型基础认知
学习目的:理解推理模型与GPT模型的本质区别,掌握根据任务特征选择模型的决策方法。
学习内容:o1/R1的技术路径对比(推理时间扩展、RL+SFT训练范式)、两类模型的优劣势分析、五要素选择矩阵(速度/成本/准确度/复杂度/可靠性)。
学习要求:能够准确判断任务类型,在速度与成本优先时选择GPT模型,在准确度与多步骤推理优先时选择R1系列模型。
推理模型实战应用
学习目的:掌握推理模型的核心应用场景与高效提示工程方法,提升复杂任务解决能力。
学习内容:四大核心场景(模糊任务理解、海量信息检索、关系发现、多步骤代理规划);提示词三大原则(清晰性降低熵、结构化引导路径、细节化压缩空间)及正反案例对比。
学习要求:能运用结构化提示词框架解决实际业务问题,避免"逐步思考"等冗余指令,实现精准推理。
技术深度与系统架构
学习目的:理解推理能力提升的数据本质,掌握多模型协同架构设计与技术趋势判断。
学习内容:关键数据策略(代码/数学数据占比提升、退火阶段调整参数)、三阶段Scaling Law智能叠加原理、多模型组合架构(推理模型作"大脑"规划+GPT作"手脚"执行)及POC实践边界。
学习要求:能设计端到端的多模型协同方案,理解蒸馏与复现的本质区别,把握模型多元化应用方向。