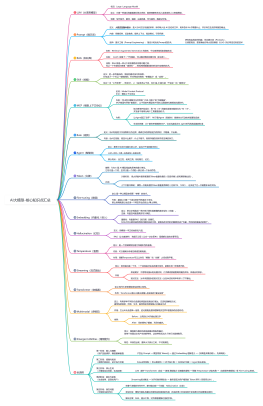
LLM(大语言模型)
名词:Large Language Model
定义:它是一种通过海量数据训练出来的、能够理解和生成人类语言的人工智能模型。
场景:写作助手、翻译、编程、头脑风暴、学习辅导、数据分析等。
Prompt(提示词)
定义:<b>人机交互指令设计</b>,是人与AI交互沟通的桥梁,即你输入给 AI 的任何文本,用来告诉 AI 你需要什么,并引导它生成你期望的输出。
内容:明确任务,设定角色,提供上下文,指定格式,引导风格
延伸:提示工程(Prompt Engineering):指设计和优化Prompt的技术。
研究和实践如何构建、优化提示词(Prompts),<br>以便更高效、更准确地引导大语言模型(LLM)执行特定任务的技术
RAG(知识库)
名称:Retrieval-Augmented Generation 的缩写,中文意思是检索增强生成
内容:(LLM)配备了一个专属的、可以随时更新的图书馆(知识库)。
流程:RAG 就是一种让大语言模型在回答问题之前,<br>先从一个外部知识库里“查资料”,然后再根据查到的资料进行回答的技术。
Skill(技能)
定义:把一系列复杂的、固定的提问技巧和流程,<br>打包成了一个可以一键调用的、针对特定任务的“专属能力”或“应用”。
给AI一本“工作手册”,告诉它1、2、3应该怎么干活,Skill 是 AI 能力的“产品化”和“服务化”
MCP(模型上下文协议)
名词:Model Context Protocol<br>中文:模型上下文协议
内容:可以把它理解为AI世界的 "USB-C接口"或"万能插座",<br>MCP就是AI界的"普通话",让不同的AI模型和不同的工具能够无障碍地沟通协作。
作用:
极大降低开发成本:将 "M × N" 的复杂连接问题简化为 "M + N" 。<br>开发者不用再为每个工具重复造轮子。
让Agent真正"动手":MCP是Agent(智能体) 能够自主行动的关键基础设施
生态的关键:大厂都在积极拥抱MCP,它正迅速成为AI agent时代的底层通用标准
Rule(规则)
定义:给AI划定的工作流程和行为边界,确保它在发挥创造力的同时,不跑偏、不出错。
内容:给AI立规矩,规定什么能干,什么不能干。极其详细的说明书或法律的条文。
Agent(智能体)
定义:拥有了自主行动能力的LLM,会自己干活的数字员工
LLM+记忆+工具+任务规划+自助决策
核心特点: 自主性、使用工具、规划能力、记忆。
Token(令牌)
解释:Token 是 AI 模型阅读和思考的最小单位。<br>它可以是一个词,也可以是一个词的一部分或一个标点符号。
作用<br>
计费标准: 绝大多数AI服务都是按Token数量收费的(包括你输入的和模型输出的)。<br><br>
上下文窗口限制: 模型一次能处理的Token数量是有限的(比如1M、128K),这决定了它一次能看多长的文档。
Fine-tuning(微调)
定义:是一种让模型变得更“专精”的技术。
作用:基础LLM是一个读过很多书的通才大学生,<br>那么微调就是让他去读一个特定专业的硕士/博士课程。
Embedding(向量化 / 嵌入)
定义:把文字转换成一串只有计算机能看懂的数学坐标(向量)。<br>注意:向量空间里是真实可计算的。
重要性:向量是RAG(知识库)的基石。<br>RAG之所以能快速找到和问题相关的文档,就是先把文档和问题都变成了向量,然后找距离最近的那个。
Hallucination(幻觉)
定义:指模型一本正经地胡说八道。
RAG(让它查资料) 和提示工程(让它一步步思考) 是缓解幻觉的主要手段。
Temperature(温度)
定义:是一个控制模型创造力和随机性的参数。
内容:可以理解为学者的思维发散程度。
作用:调整Temperature可以让你在“精确”和“创意”之间找到平衡。
Streaming(流式输出)
定义:流式输出是一个字、一个词地实时生成并展示给你,就像水流一样源源不断。
作用
体验更好:不用等待漫长的处理时间,几乎瞬间就能看到回复的开始,体感会好很多。
实时交互:为未来更复杂的实时交互(比如AI实时同声传译)打下基础。
Transformer(变换器)
定义:现代大语言模型背后的核心架构。
作用:Transformer是让AI真正读懂人类语言的"魔法发明"
Multimodal(多模态)
定义:利用多种不同形式或感知渠道的信息进行表达、交流和理解的方式,<br>通常包括视觉、听觉、文本、触觉等多种感官输入和输出方式
作用:它让AI从处理单一信息,进化到能处理和理解现实世界丰富复杂的信息形态。
举例:
Before:之前的LLM只能处理文字
After:同时拥有了眼睛、耳朵和嘴巴。
Emergent Abilities(涌现能力)<br>
定义:涌现能力是指当系统规模达到临界值时,<br>简单个体通过交互产生的新特性,这些特性无法从个体行为直接推导。<br><br>
特性:非线性出现、整体大于部分之和、不可预测性。
全流程
第一阶段:输入与理解<br>(用户发起请求,模型理解意图)
户发出 Prompt → 模型将其 Token化 → 通过 Embedding 理解语义 →(如果是多模态输入,先做转换)
第二阶段:增强与规划<br>(调用外部知识,设计执行方案)<br>
Rule决定流程 → RAG查资料 → MCP连工具 → Skill执行功能 → Agent自主规划。
第三阶段:核心生成<br>(大模型综合信息,生成回答)
LLM(基于 Transformer)启动 → 调用 涌现能力 处理复杂逻辑 → 根据 Temperature 决定风格 →(如果是专精领域)受 Fine-tuning 影响。
第四阶段:输出与呈现<br>(生成结果,返回给用户)
Streaming实时推送 → 对齐机制保障安全 → 最终呈现为用户看到的 Token 序列(即回答文本)。
第五阶段:潜在问题<br>(可能发生的状况)
在整个流程的任何环节,都可能出现一个问题:Hallucination(幻觉)
发生阶段:模型可能生成看似合理但实际错误的内容(尤其在第二阶段信息不足或第三阶段推理失误时)
解决方案:RAG、提示工程、对齐都是缓解幻觉的手段。