
AI大模型应用实战知识体系v1.1.0
2026-05-09 10:47:44 0 举报仅支持查看
AI智能生成
AI大模型应用实战知识体系v1.1.0
AI
模板推荐
作者其他创作
大纲/内容
AI大模型应用实战知识体系v1.1.0
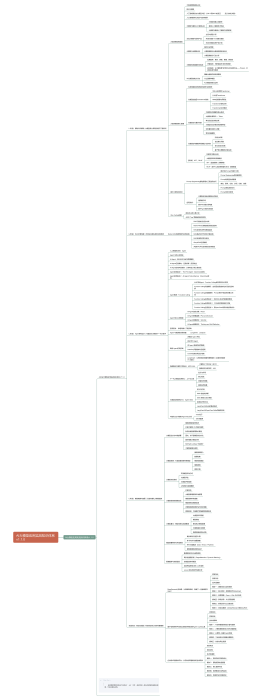
AI企业大模型应用实战知识体系 V1.1.0
L1阶段:基础认知破局 | 大模型核心原理与提示工程特训
大语言模型的基础
大语言模型基础认知
初识大模型
人工智能演进与大模型兴起:从AI1.0到AI2.0的变迁
定义与核心概念
AI1.0:感知智能时代
定义
传统AI1.0代表产品
AI2.0:认知智能时代
定义
AIGC现代AI代表应用
人工智能的核心能力与应用场景
大模型与通用人工智能认知
大模型深度认知解析
通用人工智能技术特征
大模型与通用人工智能之间的联系
主流大模型与应用产品
主流大模型介绍
DeepSeek
Qwen
GLM系列
LLama系列
GPT系列
Claude
Gemini
开源大模型 VS 闭源大模型
主流大模型应用产品介绍
深度求索
通义千问
文心一言
智谱清言
ChatGPT
大模型行业赋能分析
重点行业预测
大模型赋能行业通用场景应用分析
大模型赋能分行业分析
大模型+金融
大模型+政务
大模型+医疗
大模型+法律、游戏、教育、电商等
大模型的发展趋势与挑战
发展趋势:更快、更强、更懂、更全能
关键挑战:光鲜背后的“成长的烦恼”
应对挑战:让大模型更“好用”的三种主要方法——Prompt、外挂知识库与微调
AI大模型的能力认知
理解大模型的训练和推理
什么是概率模型
AI大模型的能力边界
大语言模型核心原理
大语言模型和传统的机器学习的差异
大模型的底层Transformer架构
为什么会用到Transformer
什么是Transformer
RNN的原理与局限性
Transformer架构分析
Transformer论文解读
大模型运行基本机制
大模型如何理解和表示单词
大模型处理单元 — Token
单元的远近亲疏关系
大模型词义的载体和表现特征
词向量和词嵌入详解
常见向量模型
大模型如何理解并预测输入的内容
注意力机制
自注意力机制
多头注意力机制
基于语义理解的内容生成
预训练、SFT、RLHF
机器学习算法分类
大模型预训练流程解读
SFT(监督微调)流程解读
RLHF(基于人类反馈的强化学习)流程解读
提示工程综合特训
Prompt Engineering基础原理与工程进阶技巧
提示词(Prompt)与提示工程
Prompt Engineering的构建原则
Prompt的典型构成要素
角色、要求、任务、示例、约束、流程
Prompt调优进阶技巧
零样本提示
少样本提示
思维链(Chain-of-thought)
自洽性(Self-Consistency)
思维树(Tree-of-Thought)
反思机制(Self-Reflection)
Prompt攻击与防范
提示词注入
提示词防范
应用实战:
大模型应用全流程提示词实战
通用提示词
基于RAG提示词构建
基于Agent提示词构建
基于任务提示词编写
Agent Skills中提示词的使用
腾讯龙虾QClaw基本使用
Prompt Engineering实战应用集
字节Coze平台概述
Coze是什么
Coze能做什么
注册账号
应用实战:基于提示工程的旅游攻略系统实现(基于最新Coze2.0)
应用实战:企业运营成本分析核算(升级版)
Prompt Engineering 优化和经验总结
Vibe Coding详解
国内外主流工具介绍
国内
字节 Trae
腾讯 CodeBuddy
阿里 Qoder
国外
Claude Code
Cursor
CodeX
AIIDE Trae 零基础到应用实践
L2阶段:RAG引擎构建|打造企业级私有知识库系统
Native RAG构建流程与应用实践
RAG 架构的价值与未来
直面挑战:LLM 的核心能力缺陷与商业化瓶颈
范式革命:RAG 架构的检索-增强-生成协同工作流全景解析
技术演进之路:高级 RAG 的协同范式演进
Native RAG从基础理论到实战应用
智能知识库构建与数据工程
数据源的高效集成与预处理:文档加载与读取
兼顾语义完整性与检索效率:文档分块策略
语义向量化的核心技术深度解析
从 Embedding 理论到工程价值
向量定义与向量化的意义
向量化实践
主流向量模型的API 集成
基于Ollama的向量模型本地部署
核心相似度算法原理与应用
余弦相似度Cosine核心算法原理
欧式距离L2核心算法原理
高效检索的关键:Top-K 语义索引与查询优化
高性能向量数据库选型与实战
业界全景扫描:主流向量数据库核心功能与性能横评
主流向量数据库选型指南
Milvus
FAISS
Pinecone
Postgres
Redis
云上向量数据库
轻量级向量数据库 Chroma 的应用场景与商业价值介绍
深入向量检索内核|核心算法原理剖析
IndexFlatL2算法原理解析
IVF-PQ算法原理解析
HNSW算法原理解析
应用实战:向量检索HR制度智能问答系统
应用实战:混合检索医疗实体命名实战
RAG应用主流开发框架实践
Langchain 零基础到应用实践
什么是LangChain?
LangChain 的核心思想与组件化架构
LangChain体系概览
Langchain的核心组件
LangChain应用程序生命周期
LangChain之Model I/O
Model 模型
提示模板
创建提示模板
直接生成提示模版
提示模板和大模型结合起来
ChatPromptTemplate聊天提示模板
输出解析器
链(chain)
跟踪和调试
发布应用程序
增强提示词模版和输出解析器
增强提示词模板
少量样本示例的提示模板
提示模板部分格式化
增强输出解析器
Langchain的链和LCEL详解
链的基本使用
LCEL高级特性与组件
RunnableLambda
RunnableParallel
RunnablePassthrough
应用实战:多用户聊天机器人实战
应用实战:LCEL内置链读取在线WEB网页实战
应用实战:电商客户智能反馈处理系统
查看链的元数据及其输入输出
赋予应用记忆:LangChain 的多轮对话管理机制
RunnableWithMessageHistory
ChatMessageHistory的使用
RunnableWithMessageHistory
应用实战:多用户聊天机器人对话记录持久化实战
在 LangChain 中构建 RAG 应用
文档加载与数据注入
文档转换器
文本嵌入与向量化
向量数据库的存储与索引
链接大模型实现增强生成
检索器的配置与召回
应用实战:基于LangChain的在线网页的RAG实现
应用实战:基于LangChain的企业知识库RAG实现
LangChain 的工具(Tools)调用
连接真实世界:工具Tools
应用实战:使用工具查询数据库表
LangChain访问MySQL数据库
如何将工具和大模型进行绑定
如何使用LangChain内置工具
LangChain查询数据库表实践
应用实战:基于LangChain的个人全能助手
访问本地浏览器
自定义生活导航
使用本机工具
langchain v1.0新特性展望
LlamaIndex 核心架构与流程解析
LlamaIndex 核心理念解读与快速上手
Llamaindex是啥
Llamaindex快速入门
什么是代理?
工作流是什么?
什么是上下文增强?
基础LlamIndex 构建 RAG Pipeline
Loading
Documents
Node
节点解析器
独立使用
变化使用
数据连接器
节点解析器
文件节点解析器
HTML 节点解析器
JSON 节点解析器
Markdown 节点解析器
文本分割器
代码分割器
语言链节点解析器
句子分割器
语义分割节点解析器
分词文本分割器
Indexing
向量存储索引
组合检索
属性图索引
简单 LLM 路径提取器
隐式路径提取器
动态路径提取器
文件索引管理
Insertion 插入
Deletion 删除
Update 更新
Refresh 刷新
Document Tracking 文档跟踪
元数据提取
自定义提取器
Storing
向量存储
文档存储
索引存储
键值存储
自定义存储
Querying
查询引擎
聊天引擎
Evaluation
响应评估
响应忠实度
评估查询+响应相关性
问题生成
批量评估
deepeval深度评估
探索复杂 Workflow 与数据代理
Workflow的核心组件
定义工作流事件
设置工作流程类
工作流入口点
工作流程退出
绘制工作流程
全局上下文/状态协同
多事件等待
手动事情触发
人机协同
逐步执行
检查点工作流程
部署工作流
Workflow管道
基本工作流
工作流分支与循环
状态维护
流媒体事件
并发执行
子类化工作流
嵌套工作流
可视化工作流
RAG痛点分析与优化方案实践
RAG商业化落地九大痛点分析
痛点一:文档加载的准确性与效率问题
痛点二:文档分块粒度的最优解困境
痛点三:错过排名靠前的文档,关键信息沉底的问题
痛点四:召回上下文的精准度与相关性低的问题
痛点五:最终答案的格式错误或混乱的问题
痛点六:答案不完整,生成的答案内容不完整或被截断
痛点七:内容提取失败:未能从上下文中提取到有效答案的问题
痛点八:回答过于具体或过于笼统,不符合用户预期
痛点九:事实一致性的终极挑战:幻觉难题
破局之道 - Advanced RAG 技术栈与实战
Advanced RAG 核心原理与技术矩阵
Advanced RAG 场景概述与全局视野
企业级 RAG 数据清洗系统
系统遵循“读取 -> 编排 -> 清洗 -> 追踪”的四层模型
数据清洗
针对 PDF、Word 等复杂文档的深度解析与结构化
数据增强
主动生成元数据或摘要,为后续检索铺路
Pre-Retrieval预检索
多维索引策略
摘要索引 (Summary Index)
父子索引 (Parent-Child Retriever)
假设性问题索引 (Hypothetical Question Index)
元数据索引 (Metadata Index)
索引小结
查询优化
Enrich完善问题
Multi-Query 多路召回
Decomposition 问题分解
HyDE假设性文档嵌入
查询优化小结
检索优化-混合检索
检索优化-混合检索核心原理解读
检索优化-混合检索适用场景分析
实现检索优化-混合检索实现策略
Post-Retrieval后检索
重排序
Reranker模型
LongContextReorder
重排序底层原理
RAG-Fusion
上下文压缩和过滤
Advanced RAG 核心优化策略实战
应用实战:三种方式实现多模态知识库的图文智能检索
应用实战:金融助手RAG 实战
应用实战:企业级RAG数据清洗系统(四层模型:读取→编排→清洗→追踪)
应用实战:通用文档智能问答系统商业化实战(录播补充)
RAG应用的评估与优化
评估方法
人工评估:作为质量评估的黄金标准
自动化评估:实现规模化、可重复、高效的量化评估
评估类型和评估指标
检索质量评估
上下文相关性( Context Relevancy)
上下文精度( Context Precision)
上下文召回率( Context Recall)
生成质量评估
忠实度(Faithfulness)
答案相关性(Answer Relevancy)
评估指标总结
常用的评估工具介绍
Ragas
四大评估指标与应用
Trulens
如何追踪和评估 LLM 应用的完整生命周期
应用实战:构建 RAG 性能诊断与优化闭环(医疗场景)
性能基线建立|如何通过指标判断RAG应用的性能
瓶颈诊断分|诊断RAG应用性能瓶颈
制定优化策略|RAG应用针对性优化策略
设定行业基准|RAG性能指标范围和行业阈值
应用实战:参数调优实验 - 探寻最优知识块大小
为什么知识块大小很重要
通用场景推荐
细分场景推荐
知识块大小评估实战
评估参数
评估结果
评估结论
应用实战:2023全球智能汽车AI挑战赛
结果分析与综合评价
重排序模型提升RAG应用性能
GraphRAG应用解析
知识图谱与 Neo4j 实践
为什么要使用知识图谱
知识图谱三元组
Neo4j 安装
FAQ 图谱构建
图谱可视化工具
RAG + KG 联合推理
GraphRAG原理
概述
发展历程
工作流
索引阶段
第一阶段: 生成知识图谱
文本切分
提取实体和关系
构建知识图谱 (KG)
第二阶段:社区集群
社区划分和层级结构
社区总结
查询阶段
本地搜索
全局搜索
DRIFT 搜索
GraphRAG应用场景分析
GraphRAG项目部署
开源RAG平台应用项目应用实践
RAGFlow应用分析
RAGFlow 基础认知
什么是 RAGFlow?
RAGFlow vs. FastGPT vs. Dify:对比与选择
RAGFlow 实战操作
本地部署
应用实战:构建AI医疗问诊助手
FastGPT应用分析
应用实战:实时网页信息爬取+RAG的问答系统搭建及发布
L3阶段:Agent架构设计|构建自主决策的下一代AI助手
人工智能的未来:Agent
Agent 生态认知革命
AI Agent:核心定义与运作原理解析
AI Agent任务解构:任务拆解|反思改进
AI Agent应用开发框架:从架构设计到工程实践
Agent应用实战 1:The First Agent(OpenClaw版本)
Agent应用实战 2:AI Agent+Tools+Memory(OpenClaw版本)
Agent智调:Funcation Calling
从API到Agent:Function Calling诞生的技术必然性
Function Calling机制解析:自然语言到结构化执行的范式转换
Function Calling全链路解析:Prompt到API响应的完整工作流
Function Calling应用实战 1:动态SQL生成与数据库查询
Function Calling应用实战 2:12306实时票务接口对接
Function Calling应用实战 3:用OpenClaw调用本地系统命令
Agent 核心认知框架
AI Agent实时决策:React
AI Agent策略蓝图:Plan-and-Execute
AI Agent回路验证:Self-Ask
AI Agent偏差修正:Thinking and Self-Reflection
应用实战 :命理机器人工程实践
Agent 可观测性系统构建
LangSmith、Langfuse
高级 Agent应用实践
多模态 Agent 开发
自主学习 Agent
多 Agent 系统的协同智能
多Agent协作系统
多智能体系统(MAS)核心理论
从单一Agent 到多智能体系统 (MAS)的演进
什么是多智能体系统 (MAS)?
应用领域
AutoGen多智能体对话框架
AutoGen介绍
AgentChat
AutoGen Studio:让AI开发像搭积木一样简单
应用实战:短视频自动生成工具
应用实战:多智能体协同代码生成应用
应用实战:网页浏览多智能体实战
CrewAI任务协同设计框架
CrewAI基础认知
安装部署
应用实战:Job Posting(职位发布)
应用实战:用OpenClaw实现协作场景
LangGraph:从线性链式到循环图智能体(全面支持最新V1.0版本)
核心概念与基础
从 LangChain 的“链”到 LangGraph 的“图”
LangGraph 概述
架构基石:节点 (Nodes)、边 (Edges) 与状态 (State)
基本概念
Graphs 图
状态图
编译图
State 状态
Schema模示
Multiple schemas 多模式
Reducers 归约器
在图状态中处理消息
Nodes 节点
START Node 节点
END Node 节点
添加节点到图 (add_node 方法)
Edges 边
Normal Edges 正常边
Conditional Edges 条件边
Entry Point 入口点
Conditional Entry Point 条件入口点
核心术语
Send 机制
Map-reduce
Command
Human-in-the-loop 人机交互
Persistence 持久性
Checkpoints 检查点
Threads 线程
Configuration 配置
interrupt 中断
Breakpoints 断点
Subgraphs 子图
Visualization 可视化
Streaming 流式传输
实践: 构建聊天机器人
核心术语与OpenClaw对比
OpenClaw简介(GitHub 28.5万星标)
对比:OpenClaw的快速上手体验
OpenClaw的工具调用机制
OpenClaw Skills体系深度解析
开发自定义Skill(跨框架对比)
对比:OpenClaw vs AutoGen
OpenClaw与LangGraph的设计对比
高级特性与实战指南
入门实践:Graph API 的构建、编译与执行
如何从节点更新图状态
如何创建步骤序列
如何创建并行执行的分支
如何创建用于并行执行的MapReduce分支
如何创建并控制具有递归限制的循环
如何可视化图
对图执行的细粒度控制
如何在图和子图中更新状态并跳转到节点
如何为您的图添加运行时配置
如何添加节点重试策略
如何在达到递归限制前返回状态
长时记忆:Checkpoints与状态持久化
如何为图添加线程级持久性
如何为子图添加线程级持久性
如何为图添加跨线程持久性
如何使用Redis创建自定义检查点器
内置内存管理与状态追踪
如何管理聊天记录
如何删除消息
如何添加会话历史摘要
人机协同:实现人在环路
如何使用interrupt等待用户输入
如何审查工具调用
如何编辑图状态
可靠的工具调用与错误重试机制
如何使用 ToolNode 调用工具
如何处理工具调用错误
如何将运行时值传递给工具
如何传递配置给工具
如何从工具更新图状态
如何处理大量工具
模块化设计:使用子图构建复杂应用
如何使用子图
如何查看和更新子图的状态
如何转换子图的输入和输出
构建多智能体(Multi-Agent)协作系统
细粒度控制
长时记忆
人机协同
错误重试
子图构建
Multi-Agent高级特性
综合实战项目
应用实战:基于LangGraph的旅游规划智能体
应用实战:完全基于OpenClaw的综合实战(压轴项目)
构建复杂大模型工程协议:MCP+A2A
大模型上下文协议(MCP)
MCP核心组件解读
MCP主机
MCP客户端
MCP服务器
MCP服务器生命周期
创建阶段
运行阶段
更新阶段
MCP生态介绍
关键采用者
社区驱动的MCP服务器
SDKs和工具
MCP平台使用
应用实战:股票分析助手
智能体交互新范式:A2A
A2A工作原理
A2A协议
MCP协同A2A
下一代大模型应用核心:上下文工程
定义与作用
核心挑战
关键技术策略
典型应用场景
大模型应用的执行力:Agent Skills
定义与作用
Skills 的结构详解
Skills 的核心设计原理
实现自己的Skills
LangChain与Skills的集成实战
LangChain与OpenClaw Skills的集成实战
可视化Agent框架/Agent IDE介绍
Coze扣子
功能与优势
插件使用及自定义插件开发
工作流
什么是工作流
工作流和对话流的区别
工作流在Coze中的表现形式
使用工作流
图像流
什么是图像流
使用图像流
知识库
什么是知识库
为什么需要知识库
上传知识库
使用知识库
数据库
什么是数据库
使用数据库
开源版coze本地部署
应用实战 :Coze实践文章总结
应用实战 :Coze实践正装形象生成器
应用实战 :Coze实践访客管理系统
应用实战 :Coze实践AI资讯助手
Dify专题课
认识 Dify
Dify 本地部署
Dify插件开发
什么是Dify插件开发?
为什么选择开发 Dify 插件?
插件类型
开发流程
零代码实现Dify插件开发
应用实战:房产数据分析报告
应用实战:房产数据分析图文
应用实战:基于多模态文生图、文生视频
应用实战:基于Dify复刻 OpenAI Deep Research
L4阶段:模型精调与部署|打造专属化大模型服务
大模型生态与本地部署
模型微调的前导知识
模型微调的定义与特征对比
模型微调的选择必要性
开源大模型 VS 闭源大模型
闭源模型局限性
开源大模型的优势
私有化模型部署的必要性
数据安全与隐私保护
业务定制化需求
性能与稳定性
成本可控与长期价值
国内、外开源模型综合对比
生态能力
性价比区间对比
性能基准对比
医疗健康大模型分析
在线问诊
LlaMA-7b 中文
Consult医疗大模型
医患对话与问答
GPT4o
扁鹊健康大模型
MoPaaS LLMops 平台简介
平台登录
密钥管理
文件存储
AI 市场
模型调优
模型管理
模型服务
大模型部署与使用
平台算力应用规则
应用实战:本地私有化部署 DeepSeek-R1-Distill-Qwen-1.5B
部署方法1:使用transformers库本地部署DeepSeek-R1-Distill-Qwen-1.5B
部署方法2:使用vLLM框架快速部署DeepSeek-R1-Distill-Qwen-1.5B
可视化大模型:使用Gradio搭建可交互的网页chatbot
扩展实践:实现自定义的单轮对话和多轮对话
大模型微调:打造垂直领域专家模型
模型微调简介
为什么需要模型微调?
数据收集
通用微调数据
领域微调数据
不同数据配比下的微调效果对比
通用优质微调数据集推荐
领域微调数据收集方式
网络爬虫
大模型蒸馏数据
基于下游任务数据集构造
确定备选模型
微调模型测试题收集
模型微调
PEFT 主流技术介绍
Adapter Tuning原理解析
Prompt Tuning原理解析
Prefix Tuning原理解析
LoRA 低秩适配微调
算法原理解析
性能效果分析
Freeze微调
参数冻结原理解析
性能优缺点分析
如何选择
全参微调 VS PETF微调
全参微调与PETF微调成本对比
微调工具
LLaMA-Factory框架介绍
Swift 框架介绍
大模型评估体系
开源模型评估方式
自动化评估
Precision
Recall
F1-Score
Accuracy
BLEU
ROUGE
Bertscore
人工评估
明确评估维度
常见评估维度
选择评估者
制定评估指南
实施评估过程
结果收集
大模型评估
基于大模型的逐点评估
基于大模型的对比评估
大模型评估框架
评估内容和标准
评估的目标
评估框架解析
HELM
SuperCLUE
C-Eval
MedBench
A/B测试与因果推断
大模型微调全链路实战
开源生态
Hugging Face
摩搭社区 ModelScope
Hugging Face 核心库
大模型推理框架本地部署
部署方法1:使用transformers库本地部署
部署方法2:使用vLLM框架快速部署
可视化大模型:使用Gradio搭建可交互的网页
多轮对话:实现自定义的单轮对话和多轮对话
模型微调环境准备
大模型微调成功因素
数据集和处理方法
LoRA微调原理和微调工具
环境安装
数据处理
模型微调全链路实操
数据格式选择
LORA参数选择
模型训练超参数选择
模型训练超参数优化
多轮对话实例
数据格式转换
模型参数对比
训练效果监控
评模型微调成果评估与优化策略
自由文本转换为对话数据
数据去重和相似度过滤
质量检测与过滤
合并Lora Adapter与原模型
测试大模型
计算自动化指标
自由文本转换为对话语料
数据去重与相似度过滤
数据质量检测与过滤
微调实战:打造医疗领域模型微调实战
微调数据构造
指令微调数据的基本格式讲解
常见的数据预处理方法实践
微调方法1:手动构建微调代码,微调Qwen2.5-0.5B-Instruct模型
微调方法2:使用LLaMA-Factory开源框架微调Qwen2.5-0.5B-Instruct
效果对比:微调前后的模型的推理实践,以及效果的对比
大模型量化:模型压缩与加速推理
大模型知识蒸馏
模型剪枝
移动端大模型部署
大模型量化全流程
量化概述
大模型量化方法介绍
实操
加载 FP16 模型并记录性能基线
执行 GPTQ 量化(4-bit)
加载量化模型并测量性能
量化前后性能对比实践
量化中的变化因素
量化策略和精度提升方法
高精度量化方法
量化策略和提升方法
平滑量化smoothquant
激活感知量化AWQ
权重重要性分析
混合精度量化
微调和量化联合训练
QAT 量化感知微调
QLoRA 量化低秩适配微调
蒸馏-量化协同训练
QAT 与 QLoRA 联合训练
模型部署架构与环境规划
硬件规划与显存计算
单卡与多卡部署策略
并行方案概述(Data / Tensor / Pipeline)
模型部署系统架构设计
GPU 检测与显存估算
单卡部署 vLLM 推理服务
多卡部署 DeepSpeed 推理
Pipeline 并行演示
推理服务与运维监控
推理框架对比与选型原则
高并发推理机制(PagedAttention / Dynamic Batching)
运维监控体系概览
启动带监控端口的 vLLM 服务
Locust 并发压测与性能分析
实战阶段:商业实战篇|综合商业核心项目专题精研
DeepResearch实战课:从搜索到系统,构建下一代智能研究Agent
项目亮点
业务价值驱动:解决“信息过载+决策风险”两大痛点,覆盖科研、金融、法律、商业等高频场景
技术栈前沿:LangGraph + 多智能体 + 阿里云MCP,构建可落地的DeepResearch系统
系统化实战:从RAG演进到DeepResearch,从状态图设计到部署上线,全程代码实操
企业级优化:支持研究计划生成、稳定性保障、多轮反思、可信溯源,具备工业级可靠性
项目目标
构建自主规划、多轮检索、带反思能力的AI研究Agent
使用StateGraph设计复杂推理流程
集成Qwen + 阿里云MCP实现高性能Web检索
部署具备前端界面的完整DeepResearch系统
技术栈清单
框架:LangGraph, LangChain, FastAPI, React,TypeScript
模型:Qwen系列(通义千问)
云服务:阿里云百炼平台、MCP工具中心
工具:Miniconda, Vite, Tailwind CSS, Radix UI
模块一:课程导论与业务场景
DeepResearch 解决了什么业务问题?
典型用户场景:科研、金融、法律、商业分析
效率与质量提升的量化数据
从RAG到DeepResearch的技术演进路径
模块二:核心架构:多智能体与StateGraph
多智能体系统(MAS)基础与协作模式
StateGraph 状态图框架详解
节点(Node)与边(Edge)设计原则
构建一个Planning-Reflection双循环研究代理
模块三:检索增强:Qwen + Web RAG实战
Qwen模型与百炼搜索API集成
搜索词生成与多轮检索策略
内容提取、去重与引用溯源
构建端到端的Web研究流水线
模块四:系统实现:从代码到部署
项目结构与环境配置
前后端分离架构(FastAPI + React + LangGraph SDK)
Agent基类、JsonAgent、MCPAgent、WebSearchAgent实现
部署与调试:本地开发与云服务发布
模块五:系统优化与工业级实践
ResearchPlan节点:需求澄清与计划生成
稳定性保障:重试、检查点、内存管理
可信溯源输出(Markdown报告)
模块六:总结与展望:从DeepResearch到DeepRAG
技术三级跳:网络级 → 组织级 → 生态级
能力跃迁:持续学习、闭环规划、多模态交互
挑战与对策:可信溯源、成本控制、隐私安全
未来趋势:低代码平台、开源标准、联邦检索
基于电商系统平台的全流程任务规划的Agent Copilot工具
项目亮点
真实业务场景:基于电商订单处理全流程,覆盖OMS、WMS、TMS多系统协同(仿真系统)
全栈技术实战:Python + Flask + React + Milvus + MongoDB,从后端到前端完整实现
工业级架构思维:重点解决Bad Case、边缘场景、系统稳定性等实际问题
项目目标
掌握Agent任务分解、工具选择、动态调整的核心算法
构建可处理复杂业务流程的智能Copilot系统
获得处理真实业务场景中Bad Case的系统化方法论
建立AI应用架构思维,具备设计企业级智能体能力
技术栈清单
核心框架:Agent任务规划、工具选择、参数提取、工具调用、响应生成
数据层:MongoDB数据库 + Milvus向量数据库 + 向量召回模型
服务层:Flask API服务 + React交互界面
模型层:大语言模型API深度集成与优化
模块一:AI任务编排的商业价值与前景
Agent技术:为什么是大模型应用的未来?
业务场景剖析:电商、金融、智能客服中的Copilot应用
项目蓝图:基于电商订单处理的Copilot平台设计
模块二:大模型智能体核心技术深度解读
任务规划:智能体如何将复杂目标分解为可执行步骤
工具选择:如何让智能体在众多API中精准选择最合适的工具
参数抽取:如何正确配置API使用参数
工具调用:实现语言模型与外部工具的无缝交互
响应生成:智能体如何总结执行结果并给出清晰响应
模块三:从零到一构建Copilot系统
开发环境与技术栈搭建
Python + Flask + React开发环境
大语言模型API核心功能与调用技巧
MongoDB数据库 & Milvus向量数据库:安装、部署与应用
向量召回模型原理与实战应用
系统架构设计与工程化
可扩展的Copilot系统架构设计
模块化与工程化的代码组织规范
电商订单处理流程的业务建模
核心模块代码实现
精准路由:工具选择模块实现
智能规划:任务分解与动态调整算法
参数魔法:API参数自动提取关键技术
闭环执行:工具执行与结果总结完整流程
系统部署与交付
基于Flask的API服务打包与部署
React+Antd交互式前端界面开发
系统集成测试与性能验证
模块四:工业级优化与疑难问题解决
实战复盘:典型Bad Case分析与解决方案
召回优化:向量检索准确率与效率提升
指令优化:高级Prompt Engineering技巧
精度优化:复杂边缘情况的参数提取改进
安全性保障:基于装饰器的接口权限验证机制
性能优化:线程池管理与缓存机制
人机协同:添加用户确认机制
模块五:总结与职业发展
项目复盘:知识体系与技能树梳理
未来展望:Agent技术发展趋势与应用前景
企业级HR智能体平台:从自动化到智能化的全栈实战
项目亮点
真实业务痛点驱动:精准解决招聘效率低、培训成本高、知识分散、系统割裂四大HR核心痛点
全栈技术深度融合:Dify工作流 + FastAPI & LangChain后端 + Vue3前端 + PostgreSQL,掌握完整技术链
企业级架构思维:设计AI大脑+业务系统+自动化的端到端架构,具备工业级系统搭建能力
核心技术全覆盖:RAG、工作流编排、多路召回、向量数据库等前沿技术深度应用
项目目标
架构设计能力:企业级AI应用架构思维
全栈开发能力:前后端 + 数据库 + AI集成
工程化思维:效果评估、性能优化、成本控制
技术整合能力:多技术栈协同与调试
技术栈清单
应用框架:Dify(私有化部署) | 后端:FastAPI + PostgreSQL + pgvector
前端:Vue3
核心算法:RAG、向量检索、BM25、多路召回
模块一:项目导论与架构设计
企业HR数字化转型的痛点与机遇
AI智能体在HR领域的应用场景与价值
全栈技术选型与系统架构设计
项目成功指标与评估方法
模块二:基础框架快速搭建
基于trae的前后端基础框架搭建
用户认证与权限管理系统实现
开发环境配置与调试技巧
模块三:核心服务开发
自主知识库系统深度开发
文本分段算法实现与效果评测
向量数据库实战:pgvector + Embedding
混合检索系统:BM25倒排索引 + 向量检索
多路召回与重排机制优化
知识库效果评估与调优方法论
Dify工作流高级应用
Dify私有化部署与核心概念解析
HR智能工作流编排:JD生成、简历分析、面试方案等
复杂业务流程的条件判断与异常处理
模块四:系统集成与全栈实战
前后端深度集成
两种集成模式对比:直连Dify vs 后端中转
流式响应在前端的实现与优化
智能招聘模块完整实现
智能培训与政策问答系统开发
模块五:效果评估与性能优化
A/B测试与人工评估方法论
提示词迭代优化技巧
系统性能调优与成本控制
项目部署与交付最佳实践
收藏
立即使用
Collect
Get Started

Collect
Get Started

Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

