
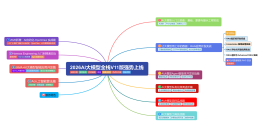
图灵AI2026版V11+AI大模型课程大纲-新版
2026-06-09 13:46:32 0 举报仅支持查看
AI智能生成
图灵AI2026版V11+AI大模型课程大纲-新版
教育培训
模板推荐
作者其他创作
大纲/内容
AI大模型入门三部曲:基础、原理与提示工程实战
学习目标
掌握大模型的基础和大模型的原理<br>
掌握使用提示工程来加大和模型的交互能力,提高模型的工作效率
Python 语言编程
第一章:Python 3 基础入门
初识 Python
Python 简介
Python 历史
Python 优缺点
Python 应用领域
数据类型
整型
浮点型
复数
数据类型转换
常量
变量与关键字
变量
变量名称
语句
表达式
运算符和操作对象
什么是操作符和操作对象
算术运算符
比较运算符
赋值运算符
位运算符
逻辑运算符
成员运算符
身份运算符
运算符优先级
字符串操作
注释
第二章:列表与元组
通用序列操作
索引
分片
序列相加
乘法
成员资格
长度、最小值和最大值
列表
更新列表
元素赋值
增加元素
删除元素
分片赋值
嵌套列表
列表方法
元组
tuple 函数
元组的基本操作
访问元组
修改元组
删除元组
元组索引、截取
元组内置函数
列表与元组的区别
列表与元组的相互转化
第三章:字符串
字符串的基本操作
字符串格式化
字符串格式化符号
字符串格式化元组
转换操作符
字符串方法
find()
join()
lower()
upper()
swapcase()
replace()
split()
strip()
translate()
第四章:字典
字典的使用
创建和使用字典
dict 函数
字典的基本操作
修改字典
删除字典元素
字典键的特性
len() 函数
type() 函数
字典的格式化字符串
字典和列表的区别
字典方法
clear()
copy()
fromkeys()
get()
key in dict
items()
keys()
setdefault()
update()
values()
第五章:条件、循环和其他语句
代码编辑器的选择
import 的使用
import 语句
使用逗号导入
别样的赋值
序列解包
链式赋值
增量赋值
语句块
条件语句
布尔变量的作用
if 语句
else 子句
elif 子句
嵌套代码块
更多操作
同一性运算符
比较字符串和序列
布尔运算符
断言
循环
while 循环
for 循环
循环遍历字典元素
迭代工具
跳出循环
循环中的 else 子句
pass 语句
第六章:函数
调用函数
定义函数
函数的参数
必须参数
关键字参数
默认参数
可变参数
组合参数
执行流程
形参和实参
变量作用域
局部变量
全局变量
又返回值和无返回值函数
为什么要有函数
返回函数
递归函数
匿名函数
第七章:面向对象编程
理解面相对象
什么是面向对象编程
面向对象术语简介
类的定义与使用
类定义
类使用
深入类
类的构造方法
类的访问权限
继承
多态
封装
多重继承
获取对象信息
使用 type 函数
使用 isinstance 函数
使用 dir 函数
类的专有方法
__str__
__iter__
__getitem__
__getattr__
__call__
第八章:异常与文件处理
异常
什么是异常
异常处理
抛出异常
捕捉多个异常
使用一个块捕捉多个异常
捕捉对象
全捕捉
异常中的 else
自定义异常
finally 子句
异常与函数
文件操作
打开文件
文件模式
缓存
基本文件方法
读和写
读写行
关闭文件
文件重命名
删除文件
对文件内容进行迭代
按字节处理
按行操作
使用 fileinput 实现懒加载式迭代
文件迭代器
StringIO 函数
序列化与反序列化
一般序列化与反序列化
JSON 序列化与反序列化
大模型的基础和原理<br>
基础认知
人工智能和大模型的强势兴起<br>
AI的发展历程<br>
大模型和通用人工智能<br>
大模型的认知和解析
通用人工智能的特征<br>
大模型和通用人工智能的联系<br>
主流大模型和大模型应用产品<br>
主流大模型简单介绍<br>
deepseek<br>
Qwen2
GLM系列
LLama系列
GPT系列
Claude
Gemini
GPT模型的发展历程<br>
ChatGPT<br>
国产大模型应用介绍<br>
深度求索
通义千问
文心一言
智谱清言
大模型的行业赋能<br>
医疗行业<br>
政务和法律行业<br>
重点行业预测<br>
大模型商业化:热潮背后的理性思考<br>
市场趋势:从通用模型走向“行业大模型+小模型”混合架构
核心瓶颈:训练数据合规、模型幻觉影响决策可信度、人才稀缺
应对策略:构建企业AI中台 + 强化评估体系 + 合作生态共建
核心原理
大模型与机器学习的本质差异<br>
传统机器学习:特征工程驱动,模型规模有限
大模型:数据驱动 + 自监督学习,参数量级突破(>10亿)
关键转变:从“人工设计特征”到“模型自动学习表示”
Transformer架构解析<br>
什么是Transformer架构?<br>
基于自注意力机制(Self-Attention)的序列建模框架
替代RNN/LSTM,实现并行化训练与长距离依赖捕捉
成为现代大模型(如BERT、GPT、LLaMA)的基础架构
为什么使用Transformer?<br>
高效处理长文本序列(克服RNN梯度消失问题)
支持大规模并行计算,显著提升训练效率
自注意力机制赋予模型“全局感知”能力
大模型运行原理探究<br>
大模型如何理解和表示单词
大模型处理单元 — Token
文本被切分为子词或字符级Token(如Byte-Pair Encoding)
每个Token映射为高维向量(Embedding)
单元的远近亲疏关系
通过位置编码(Positional Encoding)保留顺序信息
注意力权重反映语义关联强度(如“猫”与“老鼠” vs “猫”与“汽车”)
大模型词义的载体和表现特征
词向量(Word Embedding)融合上下文语义(Contextual Representation)
同一词在不同语境下生成不同向量(如“银行”→金融机构 vs 河岸)
大模型如何理解并预测输入的内容
注意力机制(Attention Mechanism)
自注意力机制(Self-Attention)
基于语义理解的内容生成
预训练、SFT、RLHF
预训练
SFT(Supervised Fine-Tuning)
RLHF(Reinforcement Learning from Human Feedback)
Prompt提示工程<br>
提示工程原理和进阶技巧<br>
什么是提示词和提示工程<br>
提示词(Prompt):输入给大模型的指令或上下文文本
提示工程(Prompt Engineering):设计高效、精准提示以引导模型输出的系统性方法
核心目标:提升模型响应质量、可控性、一致性与任务完成度
应用价值:降低微调成本,实现“零样本/少样本”快速部署
Prompt Engineering构成要素和技巧<br>
角色设定(Role Assignment)
指令明确性(Clear Instruction)
上下文构建(Contextualization)
输出格式控制(Output Formatting)
多轮对话管理(Conversational Flow)
Prompt Engineering的调优和进阶技巧<br>
零样本提示(Zero-Shot)<br>
少样本提示(Few-Shot)<br>
链式思考(思维链COT)<br>
自我一致性(自洽性,Self-Consistency)<br>
思维树(Tree-of-thought, ToT)
Prompt Engineering攻击与防范<br>
提示注入(Prompt Injection)
越狱攻击(Jailbreaking)
信息窃取(Information Leakage)
输入过滤与清洗(Input Sanitization)
模型输出审核(Content Moderation)
安全提示模板(Safe Prompt Templates)
提示工程实战
会议纪要重点提取
短剧脚本生成
实战项目:网络爆款文案生成<br>
实战项目:数据库查询SQL语句生成<br>
实战项目:基于提示工程的学员辅导系统<br>
开发者的新“心流”:Vibe Coding 全解析
什么是 Vibe Coding?
用自然语言和 AI 一起编程
快速、直觉、流畅,像“聊天”一样写代码
适合零基础入门 & 老手提效
主流工具对比
国内:字节 Trae、腾讯 CodeBuddy、阿里 Qoder
国外:Cursor、GitHub Copilot、Claude Code
Trae 实战路径
零基础:装插件 → 写提示 → 看结果
进阶:分步引导 + 多轮对话优化代码
应用:做网页、写接口、搭小项目
让大模型用上你的数据:RAG应用开发实战
学习目标
掌握使用RAG来增强模型的回复
掌握如何使用工具去评估自己的RAG的效果
掌握使用LangChain来构建基于大模型的应用<br>
掌握高级的RAG应用<br>
RAG知识库开发实战
RAG 的核心价值与应用场景<br>
解决大模型幻觉与知识滞后问题
RAG的基础概念和工作流程解析<br>
企业知识库构建
多格式文档接入(PDF/Word/HTML等)
智能分块与内容清洗策略
按照句子切片<br>
按照字符数切片
按照固定字符数<br>
递归方法<br>
Naive RAG
Embedding 技术原理与实践
核心原理
向量表示的语义本质:从离散符号到连续空间的映射
向量相似度算法:余弦相似度(Cosine)、欧式距离(L2)的适用场景对比
工程化实践
主流 Embedding 模型选型(开源 / 闭源)与性能评估
向量模型 API 调用与本地化部署优化
领域适配:微调与 Prompt 工程提升向量表征能力
向量检索系统构建
索引技术(Indexing)
倒排索引与向量索引的技术差异
“top-k” 语义检索的召回策略与相关性排序
向量存储选型与架构
主流向量数据库(Pinecone/Chroma/FAISS/Milvus)的技术特性与功能对比
企业级部署:高可用、高吞吐与低成本的平衡方案<br>
Naive RAG 核心开发与增强策略
基础 RAG 开发流程
从文档加载、向量生成到检索召回的全流程实现
基础 Prompt 设计与生成质量评估
提示词增强(Prompt Augmented RAG)
上下文管理:Prompt 压缩与相关性提升
思维链(CoT)与角色设定在 RAG 中的应用
实战项目:利用RAG知识库实现智能AI系统<br>
LlamaIndex 框架应用实战<br>
LlamaIndex 技术认知与快速入门
技术定位与生态价值
LlamaIndex 在 LLM 应用开发中的核心定位:连接非结构化数据与大模型的 “数据中间层”
与 LangChain 的技术差异与场景互补
核心概念与快速上手
代理(Agent)与工作流(Workflow)的本质:自主决策与任务编排能力
环境搭建与第一个 LlamaIndex 应用:从文档加载到智能问答的全流程实现
LlamaIndex 核心技术体系
数据加载与预处理(Loading & Ingestion)
文档与节点(Documents & Nodes):数据单元的语义拆分与组织<br>
数据连接器(Data Connectors):多源数据(文档、数据库、API 等)的统一接入
节点解析器与文本分割器:智能分块策略与噪声清洗
摄取管道(Ingestion Pipeline)的可视化配置
元数据提取与低质量内容过滤
索引技术(Indexing)
主流索引选型与场景适配
向量存储索引:通用语义检索的核心实现
属性图表索引:知识图谱与多跳推理场景
文件管理索引:结构化数据的关联检索
索引优化
动态元数据增强与索引生命周期管理
大规模数据下的索引分片与增量更新
存储系统(Storage)
存储分层设计
向量存储:主流引擎(Chroma/Milvus/Pinecone)的适配与性能优化
文档 / 索引 / 键值存储:数据持久化与缓存策略<br>
企业级扩展
自定义存储接口开发
多租户隔离与数据安全管控
查询与生成(Querying & Synthesis)
引擎核心能力
查询引擎:精准检索与结果生成的全链路调度
聊天引擎:多轮对话的上下文感知与记忆管理
高级检索增强
节点后处理器:检索结果的重排序与去重
响应合成器:多源信息的逻辑融合与格式输出
LlamaIndex 工作流(Workflow)深度开发
工作流核心架构
事件驱动模型:事件定义、触发与状态协同
核心能力:多事件等待、手动触发、人机协同与逐步执行
工程化保障:检查点(Checkpoint)与可追溯性
复杂工作流编排
基础工作流到高级场景:分支、循环、并发与嵌套
状态维护与流媒体事件处理
子类化与自定义工作流开发
可视化与部署
工作流可视化与调试工具
生产级部署:容器化与 API 服务化交付
实战项目:企业级智能知识库构建
RAG 评估与开源应用实战<br>
RAG 评估体系核心认知
RAG 效果评估指标体系
质量类指标
上下文相关性:检索片段与用户查询的语义匹配度
答案忠实度:生成内容对检索上下文的事实一致性
答案相关性:生成结果对用户需求的满足程度
能力类指标
对噪声的鲁棒性:处理低质量、冗余检索片段的能力
负面信息排除能力:识别并过滤有害、错误信息的机制
信息整合能力:多源检索片段的逻辑融合与冲突消解<br>
假设场景健壮性:对模糊、虚构问题的处理与边界识别
专业评估工具与工程化实践
RAGAS 评估框架
自动化评估原理:基于 LLM 的指标计算与结果对比
工程化落地:自定义指标配置、批量测试与报告生成
TruLens 评估平台
全链路可观测性:从检索到生成的每一步追踪
人工反馈闭环:结合人类评估结果迭代优化模型
主流开源 RAG 应用深度解析
RAGFlow:企业级检索增强引擎
FastGPT:低代码 RAG 开发平台
Dify:LLM 应用开发与运维平台
实战项目:Dify 实现数据库数据智能查询
RAG 进阶与 Advanced RAG 实战
RAG 系统缺陷诊断与优化基础<br>
核心缺陷分类与根因分析
数据处理层缺陷:文档加载准确性与效率瓶颈、切分粒度不合理导致的语义断裂
检索层缺陷:错失高相关文档、上下文与答案无关的召回偏差
生成层缺陷:格式错误、答案不完整 / 冗余、幻觉问题的触发机制
缺陷定位与量化
结合 RAG 评估工具(RAGAS/TruLens)的自动化缺陷定位
基于业务场景的缺陷优先级排序与优化路径规划
Advanced RAG 核心技术体系
Pre-Retrieval(预检索)优化<br>
优化索引策略<br>
摘要索引、父子索引:提升长文档的语义召回精度<br>
假设性问题索引、元数据索引:针对特定场景的定向检索增强<br>
混合检索:向量检索与关键词检索的融合与权重动态分配<br>
查询优化技术<br>
查询扩展:基于同义词、上下文的查询语义增强<br>
意图识别:结合 LLM 的查询重写与歧义消解
Post-Retrieval(后检索)增强
RAG-Fusion<br>
多轮检索结果的加权融合算法
动态权重调整与冲突消解机制
上下文压缩<br>
基于 LLM 的冗余信息过滤与关键信息提取
长上下文场景下的窗口滑动与摘要生成
知识图谱赋能 RAG 实战
知识图谱与 RAG 的协同价值
知识图谱概述
知识图谱的定义:实体、关系、属性的语义网络
知识图谱在 RAG 中的核心作用:解决长文本多跳推理、知识结构化问题
知识图谱 + RAG 的技术优势
对比传统 RAG:提升答案的精准性与可解释性
典型场景:复杂问答、行业知识库、智能客服
知识图谱构建全流程
知识图谱构建的核心环节
知识图谱的存储选型
图数据库基础与 CQL 实战(以 Neo4j 为例)
Neo4j 图数据库核心概念
Neo4j-CQL 核心语法与实践
提示词工程实现 GraphRAG
GraphRAG 的技术逻辑
GraphRAG 的提示词设计
Light RAG 技术体系与实战
Light RAG 核心认知
Light RAG 架构与实战案例
Light RAG 核心源码深度解析
索引阶段源码<br>
检索阶段源码
AI大模型Agent智能体开发实战篇<br>
学习目标
掌握自主搭建智能体应用<br>
掌握使用LlamaIndex构建强大的大规模索引和高效的查询工具<br>
掌握LangGragh来搭建智能体和复杂的工作流
Langchain框架开发实战
LangChain 基础认知与快速上手<br>
技术定位与生态价值<br>
基础开发环境搭建<br>
Prompt 工程与输出管控核心技术
Prompt Templates 体系
基础模板、少样本示例模板与格式化模板的设计原则
动态 Prompt 构建与组合式提示的工程化实践
示例选择器与输出解析器
Example Selectors:动态选择高相关示例提升 Prompt 效果
Output Parsers:结构化输出(JSON/XML 等)的实现与异常处理
工具链(Tools)设计与集成
内置工具深度应用
常用预制工具(如搜索引擎、计算器、代码解释器)的场景适配
工具调用的权限控制与错误处理
自定义工具开发
工具接口规范与本地能力封装
多工具协同调用的流程编排
会话记忆(Memory)系统构建
RunnableWithMessageHistory
工程化实践
为 Chain 与 Agent 添加会话记忆
多轮对话场景下的历史上下文管理
高级链(Chain)开发与 LLM 应用编排
LCEL 表达式语言
LCEL 核心语法与 Runnable 接口的工程化价值
链式调用的异步执行与错误重试机制
复杂场景编排
多 Chain 的分支、并行与条件执行
LCEL 结合 Memory 实现动态上下文感知链路
LangChain v1.0版本详解
LangChain V1.0源码剖析详解
Agent 应用开发实战
Agent 技术核心认知
Agent 技术定位与能力边界
Agent 的定义:具备自主决策、工具调用能力的智能体
Agent 核心能力:记忆功能(上下文管理)、思考与规划(任务拆解)、工具协同
Agent 技术栈与框架生态
主流 Agent 框架(LangChain Agents、AutoGen 等)的场景适配
Agent 在企业级场景的落地价值(智能助理、自动化工作流等)
Function Calling 技术原理与实践
Function Calling 核心认知
技术本质:LLM 与外部能力的接口桥梁
原理解析:从自然语言到函数参数的映射逻辑
Function Calling 多场景实战
国产大模型的 Function Calling 支持(如通义千问、文心一言)
外部 API 调用:HTTP 接口的参数封装与响应解析
数据库操作:SQL 生成与执行的安全管控
多 Function 协同:复杂任务的函数链调用
Agent 决策模型与框架
经典决策框架解析
ReAct 架构:“思考 - 行动 - 观察” 的循环决策逻辑
Plan-and-Execute 架构:先拆解任务再分步执行的规划式决策
Self-Ask 架构:通过自问自答实现多跳推理
框架选型与适配场景
不同决策框架的性能与适用场景对比
框架自定义扩展:适配复杂业务逻辑
多 Agent 系统与主流框架
多 Agent 技术认知
多 Agent 的定义:多个智能体的协作、竞争与分工
多 Agent 的核心价值:解决单 Agent 能力边界问题
主流多 Agent 框架实战
AutoGen:智能体对话与任务协同
CrewAI:角色化多 Agent 的项目流程自动化
多 Agent 的通信机制与权限管控
skills技能详解
什么是skills技能
什么时候使用?
skills文件的组成
Claude code工具
在Claude code中使用skills
langchain中使用skills能力
案例:具备skills技能的 SQL 助手
实战项目:AutoGen实现多智能体驱动的代码流程开发系统
实战项目:CrewAI实现多智能体驱动的技术情报分析与内容发布系统
LangGraph框架深度学习<br>
LangGraph 初识:定位与入门
LangGraph 核心认知
是什么:LangChain 生态下的有状态图计算框架(为 Agent 做流程编排)
为什么用:解决链式调用的灵活性、状态管理、多 Agent 协作痛点
本质:以 “状态” 为核心的图结构执行引擎
与 LangChain 的区别:LangChain 做组件拼接,LangGraph 做有状态图编排
安装与快速使用
LangGraph 基础:概念与核心功能
核心概念
状态:全流程统一数据载体
节点 / 边 / 图:图计算的基础单元
核心功能
Send/Command:消息发送与指令控制
人机交互 / 持久性 / 线程 / 存储:生产级工程能力
中断 / 断点:流程暂停与恢复
子图 / 可视化 / 流式处理:复杂流程的拆分与监控
LangGraph 实践:基础功能落地
核心能力实战
图形 API / 细粒度控制 / 持久性 / 记忆
人机交互 / 时间旅行 / 工具调用 / 状态管理
基础聊天机器人开发
搭建基础机器人
工具增强 / 添加内存 / 人机交互 / 自定义状态
LangGraph Agent 架构:多智能体设计
Multi-agent 开发
Agent 通讯方式
多智能体网络构建(工具定义 / 图节点设计)
监督器与分层 Agent Teams
主流 Agent 架构
Plan-and-Execute/LLMCompiler
反思类(Reflexion)/ 思维链类(Tree of Thoughts)
自发现 Agent(Self-Discover)
LangGraph平台
平台介绍
部署LangGragh项目
可视化AI开发框架<br>
扣子概述<br>
什么是扣子
为什么使用扣子
注册扣子
扣子的功能<br>
工作流<br>
什么是工作流
工作流和对话流的区别
工作流的使用限制
如何使用工作流
工作流节点
插件
什么是插件
创建自己的插件
知识库
知识库概述
知识库分类和使用
文本知识库
表格知识库
图片知识库
知识库分段
Scraper
提示词
设置提示词
编写提示词
调试提示词
数据库
创建数据库
使用数据库
管理数据库
音色
MCP模型上下文协议
什么是MCP?<br>
MCP原理
MCP组成元素
主机Host
客户端Client
服务端Server
MCP和Function Call对比
MCP应用场景
MCP的技术优势和行业价值
MCP使用
MCP应用的方式
常用的MCP工具
cursor
cherry studio
cline
FastAPI
MCP实战教学
AI大模型私有化微调进阶篇<br>
学习目标
掌握大语言模型本地私有化部署 <br>
掌握如何进行大模型微调
掌握根据特定任务进行垂直领域的微调
掌握多模态模型图像视频的识别
开源语言模型<br>
为什么要将大模型私有化<br>
国外开源模型介绍
LLaMA系列模型私有化部署
Hugging Face平台解析
vLLM加速原理解释
OpenLLM应用实践
Ollama架构解析
国内开源模型介绍
ChatGLM模型解析
Qwen大模型解析
DeepSeek V3/R1生态
开源模型的评估<br>
开源软件质量评估<br>
开源项目应用适配角度评估
开源模型生态的评估
开源模型应用场景与局限性
医疗行业的大模型分析
金融行业的大模型分析
教育行业的大模型分析
法律行业的大模型分析
其他行业的大模型分析
实战案例:ChatGLM大模型在Ollama上的本地部署
大模型微调<br>
模型微调的概念<br>
何为微调?为何微调
微调和 RAG 的关系
微调的技术要点与主流框架
选择合适的基座模型
任务需求<br>
模型性能<br>
计算资源
数据规模与质量
可解释性与透明度<br>
社区支持与生态<br>
数据收集和清洗
数据清洗
数据增强<br>
数据去重<br>
合成数据⽣成
微调框架的选择
PyTorch框架<br>
HuggingFace Transformers工具<br>
unsloth 框架<br>
unsloth 框架介绍
unsloth 的⽣态优势
unsloth 的开箱可⽤与⾼度可定制化
实战案例:使⽤ unsloth 微调 Llama-3<br>
PEFT参数高效微调<br>
PEFT 主流技术介绍
Adapter Tuning
Prompt Tuning<br>
Prefix Tuning
LoRA 低秩适配微调
算法原理解析
性能效果分析
LoRA 的改进与扩展
AdaLoRA ⾃适应权重矩阵微调算法解析<br>
QLoRA 量化低秩适配微调算法解析
LongLoRA 微调算法解析
微调大模型进行性能&能力评估<br>
大模型评估框架
评估内容和标准
评估的目标
评估框架工具解析
实战案例:使⽤ unsloth 实现 LoRA 微调
大模型量化实现<br>
模型显存占⽤与量化技术简介
微调中GPU算力测算算法
GPU芯片性能分析
模型运行算力要求
Transformers 原生支持的大模型量化算法
PTQ
QAT
AWQ:激活感知权重量化算法
GPTQ:转为GPT设计的模型量化算法
模型量化对比实例
实战案例:基于 unsloth 的量化演示
内存优化效果演示
加快推理速度效果演示
降低计算资源效果演示
保持模型性能效果演示
多模态模型
多模态的最新进展
为什么需要多模态?通往 AGI 的必经之路
国内外多模态⼤模型进展概览
⼤模型与计算机视觉
计算机视觉中的图像表示
常⽤视频处理⽅法
Transformers 在计算机视觉中的应⽤
图像⽣成技术概述
GANs ⽣成对抗⽹络及其变种
基于 Diffusion 扩散模型的多模态模型
图像⽣成技术涉及的隐私和法律问题
多模态模型的微调
迁移学习
零样本学习
多模态模型的优化
剪枝
量化
蒸馏
压缩
多模态模型的部署
选择模型打包格式
云侧或端侧部署的优劣
硬件加速⽅案
其它最佳实践
实战案例1:基于 BLIP 的图⽣⽂<br>
实战案例2:基于 Stable Diffusion 的⽂⽣图<br>
AI大模型项目实战篇
学习目标
掌握大模型在特定场景下的微调实战
掌握基于大模型的智能应用开发
大部分项目都是企业数据脱敏之后的真实项目
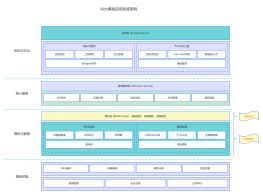
RAG知识库智能AI系统
项目简介:<br> 本项目是一个基于大语言模型(LLM)与向量检索技术构建的智能知识问答系统,采用典型的 RAG(Retrieval-Augmented Generation,检索增强生成)架构,实现了企业文档的语义理解、向量化存储与上下文增强问答能力。
技术特点:<br> 文档智能解析能力<br> 语义级知识检索能力<br> 私有化知识库构建能力<br> 上下文增强生成能力<br> 本地持久化向量存储能力
<br>
高阶工程化 RAG 系统
项目简介:<br> 本项目是一个面向复杂企业文档场景构建的高阶 RAG(Retrieval-Augmented Generation,检索增强生成)智能问答系统
技术特点:<br> MinerU 高质量 PDF 解析<br> Markdown 结构化处理<br> 表格感知切分<br> 混合检索(BM25 + Vector)<br> Chroma 向量数据库<br> LangChain Runnable 架构<br> 大模型上下文增强生成<br> 实现了针对企业年报、财务报告、招股书等复杂长文档的智能语义检索与精准问答能力。
<br>
多智能体驱动的代码流程开发系统
项目介绍:<br> 本项目是一个基于 AutoGen 框架构建的多智能体协同开发系统(Multi-Agent Collaboration System),通过模拟真实软件研发团队中的:<br> 产品经理<br> 开发工程师<br> 代码审查员<br> 测试工程师<br> 等角色,实现大模型驱动下的自动化任务协同、代码生成、代码审查与测试验证流程。
技术特点:<br> Agent 协同<br> 自动化开发<br> AI Workflow<br> 自主软件工程<br> AI Team Simulation
<br>
企业级 AI Agent Platform
项目介绍:<br> 本项目是一个基于大语言模型(LLM)、LangGraph 与 MCP(Model Context Protocol)构建的企业级 AI Agent 平台,采用微服务架构实现多智能体协同、知识库问答、工作流编排与长期记忆管理能力。<br>
技术特点:<br> 基于 LangGraph 构建多节点 Agent Workflow,实现:<br> 意图识别<br> Agent 路由<br> 状态流转<br> 工作流调度<br> 长短期记忆管理<br> 系统支持:<br> Knowledge Agent<br> Writing Agent<br> Chat Agent<br> Review Agent
<br>
大型制造企业知识库平台<br>
项目简介:<br> 这是一个面向企业内部的智能知识管理系统,旨在解决企业知识碎片化、查找效率低、经验难以传承等问题。通过将企业内部文档、规章制度、产品手册、技术方案、FAQ等各类知识进行结构化沉淀,并结合大语言模型(LLM)和智能检索技术,实现知识的智能查询、自动问答和持续更新。
技术特点:<br> 采用RAG(Retrieval-Augmented Generation)作为整体架构,通过检索增强生成有效解决大模型幻觉问题<br> 知识摄入支持PDF、Word、Excel、图片OCR等多种格式文档的智能解析、语义分块和向量化处理<br> 构建向量数据库(Milvus/Qdrant)+关系型数据库的混合存储,并结合知识图谱(实体识别与关系抽取)<br> 检索层使用向量相似度+BM25关键词+重排序模型的混合检索策略,支持多轮对话和查询改写<br> 生成层集成通义千问、DeepSeek、GPT等大语言模型,通过Prompt工程和上下文注入实现精准回答与溯源引用<br> 企业级特性包括RBAC权限控制、文档增量更新、用户反馈优化闭环及私有化部署保障数据安全
某零售企业销冠智能体Agent<br>
项目简介:<br> 销冠智能体是一个面向销售场景的AI智能体实战项目,旨在通过大语言模型和智能体技术打造“AI销冠”,帮助企业提升销售效率、线索转化率和成交能力。该智能体可模拟顶尖销售人员的行为,自动进行客户沟通、需求挖掘、异议处理、产品推荐和成交推动,实现销售流程的智能化和自动化。
技术特点:<br> 采用ReAct / Multi-Agent架构构建,支持自主规划和工具调用<br> 集成企业知识库作为长期记忆(产品、话术、客户案例)<br> 支持微信、电话、飞书等多渠道智能对话接入<br> 基于大语言模型(通义千问/DeepSeek/GPT)生成高情商销售话术和异议处理<br> 构建工具调用系统(CRM查询、报价生成、日程安排等)<br> 实现短期+长期记忆管理,支持客户全生命周期跟进<br> 结合RAG确保销售内容专业准确,并支持销售流程编排<br> 包含对话审计、合规控制和多Agent协同能力
头部视频平台大模型智能监控和预警系统
项目简介:<br>该项目利用大模型的能力,帮助某视频平台优化大数据作业流程,实现自动检测、诊断和修复数据管道中的问题,显著减少作业停机时间。<br>发挥 LLM 推理能力,通过理解日志数据、识别故障模式,从而给出建议或实施修复,提高运营效率和可靠性。
技术特点:<br>本地大模型、微调、工作流
医疗健康行业AI私人家庭医生项目
项目简介:<br>很多疾病受遗传和家庭饮食生活等习惯非常大的影响,AI私人家庭医生利用大模型技术为每个家庭成员打造每个成员的建康数据管理及私人陪伴医生。<br>永久记忆全部历史诊疗及医学检查报告等,实现专业解读、跟踪、风险评估、建议随访和答疑解惑等专业医疗服务。
技术特点:行业模型微调、RAG、MCP
VIP定制分享课程
栏目定位
为VIP学员提供高度定制化、紧跟前沿的技术与业务洞察服务。根据学员所在企业实际需求或当前最新技术动态,进行深度分析与解读,帮助学员快速抓住机会、规避风险、提升决策能力。
栏目核心价值
贴合学员真实业务痛点
快速解读新兴技术与趋势
提供可落地的建议与方案
栏目更新机制
每月1-2期(可根据需求灵活调整)<br>
两种触发方式:学员主动需求 + 团队主动发现前沿技术<br>
每次分析前与学员确认主题,确保匹配度
内容选题
企业实际需求(如销售智能化、知识管理升级、AI落地等)<br>
最新技术动态与工具(新模型、框架、应用趋势<br>
行业热点与政策变化
单篇分析内容框架
主题背景与核心要点
技术/方案原理简析
当前发展现状与成熟度评估
对企业的价值与潜在影响
落地可行性分析(成本、难度、风险)
特色模块
学员专属定制:针对某学员企业具体场景的专项分析
技术雷达:快速扫描近期的10大值得关注的技术点
落地复盘:已落地项目的效果追踪与优化建议
AI大模型工具实战篇<br>
学习目标
掌握使用Dify本地部署实现可视化和私有化的智能体应用(低代码)
使用大模型生成简历并分析,写网络爆款文案<br>
使用大模型去辅导学生学习
使用大模型去写短片脚本<br>
AI大模型进行视频创作<br>
大模型进行AI画图<br>
通过图片生成文字描述<br>
网络视频的分析描述
2026新增:AI自动化-OpenClaw 实战篇
核心概念与定位
环境部署与基础配置
核心功能教学
Skills 技能系统
本地系统操作
浏览器自动化
多 Agent 管理
安全合规与避坑指南
项目实战:构建教学 AI 助手
项目实战:Excel / 数据报表自动化
项目实战:竞品监控与内容自动发布
项目实战:智能客服与私域运营
项目持续更新中...
Harness Engineering:入门到精通实战
课程导论
AI 工程未来趋势
企业级 AI 落地真正难点
AI Harness 与传统软件工程区别
Prompt Engineering 的局限
Workflow 的边界
Agent 为什么容易失控
AI 工程范式演进
AI 工程的三次跃迁
Prompt Engineering
Context Engineering
Harness Engineering
Agent 失败模式
Harness 核心组件
上下文工程(Context Engineering)——新员工手册
Agent 专业化(Agent Specialization)
持久化记忆(Persistent Memory)
结构化执行(Structured Execution)
反馈循环(Feedback Loop)——智能体审智能体
熵管理(Entropy Management)——垃圾回收
Harness业界最佳实战案例
OpenAI:百万行代码的零手写实验
Anthropic:16 个 Agent 构建 C 编译器
Anthropic:长时间运行 Agent 的有效 Harness
Stripe:千级 PR 的 Minions 系统
Harness 行业应用落地准则
Harness 项目开发过程
信息层-让 Agent “看懂项目”
AGENTS.md 设计
项目规则描述
Agent 行为规范
docs 结构化知识库
文档组织
项目知识注入
设计文档模板
约束层 -让 Agent “不能犯错”
分层依赖检查
模块边界限制
依赖治理
自动化层 -让 Agent “自我验证、自我修复”
自动化清理 Agent
Git Worktree 自动化
可观测性接入
自我反馈系统
实战案例
从零搭建 Harness 环境
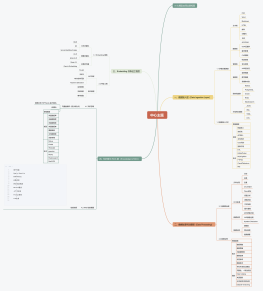
JAVA+AI大模型智能应用开发篇
AI大模型快速入门
自研大模型
门槛极高不展开
学历要求
精通算法、python、C++<br>
模型微调
DJL-Deep Java Library<br>
TensorFlow Java API
PyTorch Java API
本地大模型
ollama<br>
部署教程
jlama
部署教程
云端大模型
百炼<br>
deepseek<br>
Qwen<br>
qwq-32b
OpenAI<br>
千帆
智普
AI大模型数据整理与微调<br>
数据清洗与整理
Apache Flink数据清洗
通过LlamaFactory工具完成微调<br>
模型评估
使用测试数据集评估模型性能(如准确率、F1 分数)。
调整超参数(如学习率、批量大小)或使用更高级的优化技术(如迁移学习、知识蒸馏)
AI大模型底层协议详解与实战<br>
MCP模型上下文协议详解与实战<br>
MCP是什么MCP+SpringAI快速实现
如何通过cline和springAI使用McpServer微调
A2A智能体底层通信协议详解
Spring AI Alibaba从入门到进阶实战
课程介绍
为什么要学习Spring AI Alibaba?<br>
课程目标
掌握基于Spring生态的AI应用开发,覆盖大模型集成、RAG、Tool Calling、MCP协议、智能体等核心场景。<br>
课程特点
基于Spring生态的AI大模型应用开发,包教包会<br>
课程需要的基础
掌握SpringBoot的基础使用<br>
课程代码地址
Spring AI Alibaba基础入门<br>
课程目标:掌握Spring AI Alibaba核心组件的使用
Spring AI Alibaba的介绍<br>
Java大模型应用开发的生态<br>
Spring AI<br>
Spring AI Alibaba<br>
LangChain4j
官网地址
是什么
技术生态
核心概念
模型(Model)
提示(Prompt)
嵌入(Embedding)
Token
结构化输出(Structured Output)
微调(Fine Tuning)<br>
检索增强生成(RAG)
函数调用(Function Calling)
评估人工智能的回答(Evaluation)
环境搭建与快速入门
版本选型
JDK17
SpringBoot 3.4.0<br>
Spring AI 1.0.0-M6
Spring AI Alibaba 1.0.0-M6.1
注意事项
spring-ai 相关依赖包还没有发布到中央仓库
解决方案
完整的父POM
大模型选型
本地部署:Ollama+通义模型(Qwen)/DeepSeek<br>
实验:基于Ollama本地部署DeepSeek大模型,并通过Cherry Studio客户端访问大模型<br>
云端大模型
阿里云百炼平台
支持通义系列和DeepSeek等大模型
硅基流动平台
也支持通义系列和DeepSeek等大模型<br>
注册即送 2000 万 Tokens
实验:通过Cherry Studio客户端访问云端大模型<br>
接入大模型的方式
Ollama<br>
本地部署deepseek-r1教程<br>
DashScope<br>
类Open AI API<br>
实验:利用spring ai alibaba通过三种方式调用deepseek<br>
实验:实现你的第一个AI应用聊天机器人<br>
1)创建一个SpringBoot应用<br>
2) 通过DashScope接入大模型<br>
2.1)引入Spring AI Alibaba的依赖<br>
2.2 ) 配置application.yml<br>
2.3) 通过阿里云百炼平台创建API-KEY<br>
2.4 设置AI_DASHSCOPE_API_KEY的环境变量<br>
3)注入ChatClient实现对话接口<br>
同步接口实现
流式响应实现
完整的示例代码
4) 测试<br>
核心组件深度解析
ChatClient
作用
适用场景
详细使用
如何返回实体类型?<br>
实验:返回周星驰拍过的电影<br>
如何定制ChatClient?<br>
设置消息角色(user/system/assistant)<br>
示例
使用模版传参示例
多轮对话记忆管理
如何让大模型具有对话记忆呢?<br>
Advisor
MessageChatMemoryAdvisor
Memory<br>
InMemoryChatMemory
RedisChatMemory
使用ChatMemoryAdvisor与RedisChatMemory存储历史对话
实验
基于内存存储历史对话
示例代码
基于Redis存储历史对话<br>
示例代码
自定义RedisChatMemory
对话模型 Chat Model
Chat Model
工作原理
使用示例
Image Model<br>
文生图
使用示例
测试
Audio Model
文本生成语音
使用示例
测试
语音转文本
使用示例
测试
提示词工程
Prompt
Message
MessageType
Role
System
SystemMessage
User
UserMessage
Assistant
AssistantMessage
Tool
ToolResponseMessage
动态模板(PromptTemplate)
接口规范
PromptTemplateStringActions <br>
PromptTemplateMessageActions
PromptTemplateActions
实现方式
ConfigurablePromptTemplateFactory
示例
PromptTemplate
示例
SystemPromptTemplate
示例
变量注入技巧
实验:提示词动态注入<br>
示例
与RAG的区别<br>
结构化输出(Structured Output)
需求:文本转特定格式,比如Json、Java对象<br>
ChatClient <br>
调用entity() 方法
实体对象
List<br>
Map<String, Object>
ChatModel<br>
使用BeanOutputConverter<br>
通义千问模型参数调优
大模型是如何工作的?<br>
大模型的问答工作流程
temperature
温度值越高,模型生成的内容就越丰富多样。
top_p
top_p值越高,大模型的输出结果随机性越高。
是否需要同时调整temperature和top_p?
知识延展:top_k<br>
使用示例
Spring AI Alibaba进阶实战
目标:掌握RAG,Function Calling,MCP的使用<br>
检索增强生成(RAG)
是什么
让大模型能够回答私域知识
实验:利用cherry studio导入题库让大模型实现考题解析<br>
工作原理
建立索引阶段
检索与生成阶段
实现 RAG示例<br>
配置类
检索增强服务
RAG+阿里云百炼实战<br>
本地集成百炼智能体应用
本地RAG应用集成百炼知识库
工具(Function Calling/ Tool Calling)<br>
是什么
应用场景<br>
技术思路
和RAG的区别
实验1
Fuction Calling获取天气信息<br>
实验2
智能客服根据商品ID获取商品详情
模型上下文协议(Model Context Protocol)<br>
什么是MCP协议
Spring AI MCP
和Fuction Calling的区别<br>
MCP开发实战
通过MCP实现天气调用
stdio实现MCP服务端<br>
SSE实现MCP服务端
借助serverless将MCP Server服务部署到云端<br>
电商智能客服项目实战
课程目标:掌握电商场景下的智能对话、订单操作、智能导购等核心能力开发<br>
项目背景
开发环境
JDK17
SpringBoot 3.4.0<br>
Spring AI 1.0.0-M6
Spring AI Alibaba 1.0.0-M6.1<br>
接入阿里云百炼模型实现智能客服对话能力<br>
使用Memory实现智能客服多轮对话记忆能力<br>
实现智能客服的订单管理能力,比如查询订单,取消订单<br>
使用Trae 生成电商订单服务代码<br>
示例提示词
使用RAG接入电商客服知识库,比如订单取消规则<br>
使用Fuction Calling实现订单相关业务的调用<br>
使用MCP调用订单服务查询订单详情
实现智能客服的商品导购能力
Spring Al大模型开发框架实战<br>
Chat Client
接入openAI<br>
接入阿里百炼
接入ollama<br>
格式化输出
输出枚举
输出对象
输出Boolean/String/Integer<br>
ChatModels<br>
Advisor<br>
自定义日志对话拦截
ChatMemory<br>
对话隔离
对话持久化
Tools<br>
本地tools<br>
外部tools(MCP)<br>
MCP Client<br>
MCP Server
RAG<br>
DocumentReader<br>DocumentTransformer<br>DocumentWriter
MCP<br>
什么是MCP<br>
自定义sse方式的MCP Server<br>
自定义sse方式的MCP Client<br>
自定义stdio方式的MCP Server<br>
自定义stdio方式的MCP Client<br>
Agent智能体入门到项目实战<br>
Spring AI Alibaba Agent实战
Spring AI
Tool
记忆
结构化输出
MCP
RAG
Spring Ai Alibaba Graph
状态、节点、边基本概念介绍
Workflow工作流编排
定义自己的Node
动态编排
ReactAgent
Tool
记忆
结构化输出
RAG 架构
Hooks 和 Interceptors
内置实现
自定义 Hooks 和 Interceptors
RAG 架构
Skills 技能
在 Agent 中使用 Skills
在 Graph 中使用 Skills
最佳实践与性能建议
人工介入(Human-in-the-Loop)
中断决策类型
Workflow 中嵌套 Agent 的人工中断
最佳实践
多智能体(Multi-agent)
顺序执行(Sequential Agent)<br>
并行执行(Parallel Agent)<br>
路由(LlmRoutingAgent)<br>
监督者(SupervisorAgent)
自定义(Customized)
混合模式示例
A2A
基于 Nacos 的 A2A Registry
AgentScope-Java
更新中
Embabel-Agent
更新中
项目实战
手撸简版Manus
完成浏览器技能
完成编写代码技能
不同行业10+workflowAgent智能体开发
金融行业 - 对公信贷智能尽调与风险审批 Agent
制造行业 - 产线设备预测性维护与故障根因诊断 Agent
零售 / 电商行业 - 全渠道用户生命周期智能运营 Agent
能源行业 - 新能源电站 / 电网智能巡检与安全管控 Agent
物流行业 - 干线运输智能调度与异常全闭环处理 Agent
法务行业 - 合同全生命周期智能管理 Agent
HR 行业 - 招聘全流程自动化与人才智能匹配 Agent
医药行业 - 临床试验智能管理与合规上报 Agent
政务行业 - 企业开办与民生事项智能导办审批 Agent
房地产行业 - 案场客户全周期跟进与转化 Agent
Java大模型开发框架LangChain4J实战<br>
接入deepseek
接入百炼
接入Ollama
文生图
文生语音
整合springboot
流式输出
记忆对话
多轮对话
ChatMemory记忆对话
对话隔离@MemoryId
对话记忆持久化
角色预设
@SystemMessage<br>
@V<br>
tools<br>
RAG
什么是向量
向量文本化
向量检索
知识库RAG实战演练
文件读取解析
分词器
文本向量化<br>
检索增强
整合springboot
Agent
多模型chain式请求<br>
MCP<br>
如何接入MCP Server<br>
Java+AI大模型实战项目
智能助手客服
完整架构图
为应用接入 AI 模型服务
使用 RAG 增加机票退改签规则
使用 Function Calling 执行业务动作
使用 Chat Memory 增加多轮对话能力
实现自定义MCP Server<br>
接入三方MCP Server为智能助手赋能<br>
本地知识库
通过Ollma+AnythingLLM快速搭建本地知识库<br>
通过springai构建知识库服务<br>
为应用接入 AI 模型服务
使用redis作为向量数据库<br>
分割word、html..文本数据<br>
写入向量数据
查询相似数据
电商智能客服项目实战
课程目标:掌握电商场景下的智能对话、订单操作、智能导购等核心能力开发<br>
项目背景
开发环境
JDK17
SpringBoot 3.4.0<br>
Spring AI 1.0.0-M6
Spring AI Alibaba 1.0.0-M6.1<br>
接入阿里云百炼模型实现智能客服对话能力<br>
使用Memory实现智能客服多轮对话记忆能力<br>
实现智能客服的订单管理能力,比如查询订单,取消订单<br>
使用Trae 生成电商订单服务代码<br>
示例提示词
使用RAG接入电商客服知识库,比如订单取消规则<br>
使用Fuction Calling实现订单相关业务的调用<br>
使用MCP调用订单服务查询订单详情
实现智能客服的商品导购能力
AI人工智能算法篇
机器学习系列
人工智能概述
线性回归算法1
线性回归算法2
线性回归算法3
K-MEANS算法
特征降维
朴素贝叶斯
集成算法
逻辑回归算法
乳腺癌分类实战
支持向量机
SVM手写数字识别
随机森林
KNN算法
纪录片摇放星预测
数据降维
HOG+SVM行人检测
决策树
洛杉矶房价预测实战
聚类算法
深度学习系列
CNN卷积神经网络
PyTorch深度学习框架<br>
NLP基础和算法模型
深度学习
线性回归
二分类
多分类
迁移学习
水果识别<br>
车辆分类
多目标分类<br>
相似图像搜索<br>
目标检测
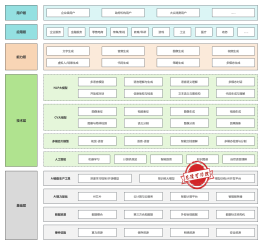
服务特色
贴心管家
学习计划制定
学员档案管理
定期回访
专属答疑
专属学员交流社群
定期学员活动
班主任督学
上课提醒
规范化课程安排
课程定期更新
工作答疑
重修权限
技术资料整合
面试指导
未来职业规划
面试指导
简历优化
内推机会
1对1面试模拟
收藏
立即使用
Collect
Get Started
Collect
Get Started
Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

