架构即未来
2019-01-28 17:08:27 0 举报AI智能生成
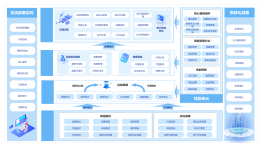
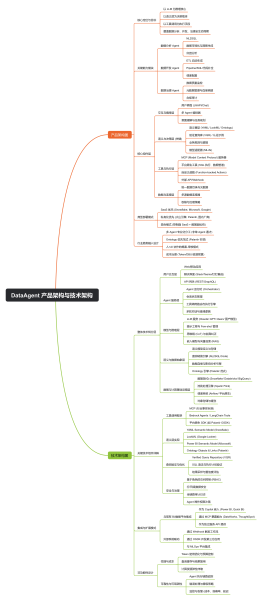
架构即未来全书思维讲解,全面的架构原则分析,通过对架构的分析形成团队管理、个人管理,领导力管理以及架构原则的详细分析
模板推荐
作者其他创作
大纲/内容






0 条评论
下一页

