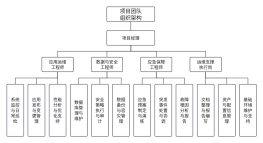
01.数据中心选型
地质环境
在选址的过程中要综合考虑问题,不应按图索骥,过于教条。
电气系统
可靠性要求
所谓全路径,指的就是从输电侧到用户侧的整条输电线路
选用产品的原则是求稳不求新。
用电安全
除了人员的用电安全之外,我们在选取机房的过程中,还要注意静电对设备的危害。
把两股线合并在一起,叫作TN-C系统,我们把这段合并的线称作PEN线。使用TNC系统可以路低成本。
PE线和N线分开与否,以及接地点的数量决定了安全等级和成本的高低
电力容量
提升机柜的利用率,是直接隆低成本的有效手段。作为主数据中心,我不推荐采用20A以下的机柜。这样的话,空间利用率不会超过70%,甚至会更低
PDU插座的数量要和电力容量以及上架设备的数量相匹配,并且应当留有独立于机柜PDU线路的插座,以供显示器、能耗仪等外接设备使用。而外接设备不应当直接接入生产的PDU插座,以防止因外接设备自身问题导致的电力故障波及生产。
空调系统
系统中都需要使用静压箱来减少动压、稳定气流,它可使送风更加均匀,从而提升制冷效果,同时还有降噪的功能。
送风模式
下出风的整体送风更均匀,温差更小,制冷效果更好。而且施工简单,无须风管和送风口。但下出风也十分考验地板材质、施工质量和布局的合理性。如果产品或施工质量不合格,会因为漏风出现送风短路。再有,地板下面容易积灰。防尘做不好的话,风机一启动就是漫天飞尘。
风冷与水冷
风冷系统需要定期换气,从外部引入新风与回风进行混合。所以,水冷效果显然在夏季要比风冷更好,而风冷的效果在冬天会得到加强。
水冷一般都会选择下出风,万一你真遇到了上出风的水冷,一定要考虑漏水是否会影响到设备的安全。
全冷
所谓显冷量是指降温时所需的冷量,而潜冷量则是指产生冷凝水所需的冷量。全冷=显冷+潜冷。
电力和空调两大系统可谓是数据中心的任督二脉。
资质要花钱,多路径也要花钱。而这些工程隐患的出现,正是一味追求低价所引发的后果。
消防系统
灭火装置应选用IG541或者七氟丙烷气体。
弱电与综合布线
弱电系统主要包括传感器监控、影像监控、门禁系统及入侵检测等。总体原则上只要做到无死角即可。
网络线路
数据中心的网络资源有专线和裸光纤两种。专线传输距离远,但租用价格高,带宽上有限制。裸光纤理论上带宽不再受限制,适合短距高、大数据量传输。同城多机房的各节点之间互通建议使用裸光纤。
03.服务器硬件选型
硬件配置
在硬件平台系统的建设初期,应当选择功能强、故障率低、日常维护简单便捷的产品。建议选择两家供应商,既减少产品多样化带来的麻烦,也防止被单一产品绑架。
当平台建设进入后期时,问题有两个:如何精简服务器的硬件配置来降低整体成本,以及如何处理生命周期完结后的老旧设备。
注意事项
内存
内存选用的重点是要确保其参数与你选择的CPU是相匹配的
网卡
如果选择万兆网卡,不一定非得采购光模块,也可以使用AOC线缆来替代
服务器规格
服务器质保期只有三年,三年以后的硬件性能会比现在提升很多,续保也需要不少的费用,与其升级配件不如直接换新机器划算
磁盘容量和数量
在硬件选型的过程当中,应当始终遵循配置最简化的原则。部件越少,出问题的概率就越低,同时成本与能耗也会相应降低。
备件供货保障期
备件供货的保障期和设备质保期相等就可以了。如果有一些机器允许超期服役(例如测试设备),备件可以从其他退役设备上拆件做替换,反正是过保的,没有必要买新的。
过保服务器的处理
服务器在这个时候如果可以完成下线,有两个比较好的处理途径。第一是回收,因为设备还没有过保,此时资产的残值相对比较高,变卖后的资金可以用于新一轮的采购。但是注意要做好数据脱敏工作,由有资质的厂家来完成相应的回收。第二是废物利用,可以把退役的设备留给测试或者内部办公使用,也可以拆件成立备件资源库。
故障率
质量是产品可用的第一要素,这里主要是指硬件的故障率。一些厂商的硬件质量甚至可以做到低于1%。不要小看这个数字的变化,对于海量模式的硬性平台,基数越大,差距效果就越明显。
带外管理
如果我们使用业务所在的链路进行消息传递和管理,我们就称之为带内(In Band),反之就是带外(Out of Band)。
异构平台融合
当平台规模从溪流模式发展到江河模式或者海量模式的时候,一些政策法规不允许只用一家的这种采购形式,同时单一化产品也存在品牌绑架的风险。
支持并使用标准的公有开放式协议是异构融合的关键。
WS-Management,全称叫作Web Services-Management,是DMTE组织基于SOAP制定的一种开源标准。该标准致力于在不同的x86设备厂商当中,提供一种IT基础架构信息访问与修改的统一接口。
除了WS-Management以外,类似的标准还有Redfish,最新版本是1.2。它是一个通过RESTful 接口利用JSON数据来实现的集成解决方案。Redfish是一个更加轻量级的协议。
用户体验
产品设计的优先级顺序应该是:逻辑性>稳定性>性能>功能。
关于产品的逻辑问题还有很多,但我想原因只有一个,归根到底是设计人员从来不用自己设计的产品造成的。
能耗测试
Turbo Boost是英特尔的睿频加速技术。这项技术可以理解为自动超频。当开启睿频加速之后,处理器会自动加速到合适的频率,并根据当前资源的占用情况实时做出调整,以此来应对多任务情况下不同进程对于性能的要求。
如果TDP是90W,意味着你的解决方案必须有能力驱散等同于90W用电能耗所带来的热量才行。实际发热量应当控制在TDP最大值的范围内。<br>TDP是热能耗的安全阈值,绝不是处理器的用电能耗。
TDP是热能耗的安全阈值,绝不是处理器的用电能耗。
分类
最大能耗
最大能耗测试用于获取服务器在最大负载的状态下所消耗的功率。
负载能耗
负载能耗比测试用于评测服务器在不同负载场景下所消耗的功率。
结果读取
ipmitool可以用,但是不是用于测量数值,ipmitool是在前期调试的过程中做横向对比分析。
磁盘性能
如果各家厂商使用的是同一款硬盘,那么性能差异就会直接体现在RAID卡上面。
网络性能
网络测试是建立在Client/Server的方式上完成的。Server 端用来侦听来自Client端的连接,Client 端血向Server 端发起网络测试,两端之间会建立起两套通道、一个通道用于传递有关测试的全部信息,另一个通道用于传递数据流量。
04.构建CMDB与workflow
问题
对于数据信息的存储和维护,完全依赖于Excel表格,而不是建立在数据库之上。
由于各个IT系统都是孤立的,当业务从一个环技流转到另处一个环节的时候,发现在IT系统层面上根本无路可走。业务流程在这种缺乏有效管理的情况下,各个系统之间的信息交换不得不依靠人工离线来完成。而在这个过程中,产生了大量的邮件、表格、会议和沟通等游离于系统之处的副产品、使得工作效率大打折扣。
核心点
70%~80%的IT相关问题与环境的变更有着直接的关系。实施变更管理的难点和重点并不是工具,而是流程。而变更管理流程自动化的实现关键就是CMDB。
评价一个运维团队的水平要看他们CMDB模型的能力成熟度。
最糟糕的运维就是在没有打好基础的时候,反倒是先把上层建筑都统统搞起来了,唯独丢掉了最重要的CMDB,用Excel表格来自欺欺人,后期信息缺失全靠人肉支撑。
CMDB的整个架构设计应当由业务团队去构建,而不是甩给开发团队。不懂业务就没有发言权。缺少对业务的深度理解,就无法全面准确地定义配置项以及建立它们之间的关系模型。
构建CMDB的出发点
关联性
提供的信息一定要和用户有关联,是用户真正希望看到的内容。
准确性
假数据比没有数据危告更大,它会导致决策者出现错误判断。
精炼性
一条信息如果不断地重复就变成了广告,所以去重也是很重要的
信息去重的方式有两种。第一是汇总。第二是升华,进行分级处理。
独特性
信息提供切忌出现常识性内容一一给的都是你不要的,说的都是你知道的。
CMDB over laas
分成三大类:第一类是资产信息,第二类是业务信息,第三类是通用信息。
硬件报修系统在发送报修申请时,可以结合CMDB把干系人的联系方式连回故障邮件发送出去,便于厂商派单,而不需要再由报修人手动填写这些信息。
要尽早地丢弃Excel记录的方式。人工记录信息往往是离散的,资产信息可以由SE协助完成,而业务信息是依靠PE去操作的,无法形成统一的信息库。
设计思想原则
预留无罪
关于CMDB构建上,有很多反对“高大全”的声音,而笔者却不这么认为,CMDB就是要“高大全”。我们提倡化繁从简,但需要减掉的是枝蔓而不是主干。
分层有理
有些人把CMDB和资产管理混为一谈。然而,CMDB并不是一个平面的架构,CMDB也是要分层级的。
CMDB在每层上需要存储的数据也不一样。要像划分功能区一样,将CMDB进行水平切割,不同层级的CMDB应由不同的团队来构建。
不许偷吃
数据的增、删、改、查都必须要通过CMDB,不允许从外部变更和获取数据。
迭代不是挡箭牌
达代的前提是,要想清楚以后会发生什么问题,并且已经做好了应对的准备,具有平滑过渡的能力。
杜绝两只手表
遇到必须采用人工录入的信息,应当使用工具或者流程规范去约束录入行为,从而降低出错的可能性。
workflow
Workflow是规范的实例化体现,它是一套嵌入流程的自动化工作系统,主要的作用是确保用户执行过程的标准化、规范化。
05.构建IAAS平台系统
选型
Kickstart
手工的弊端
执行效率主要受限于两个因素:一是手动选择浪费大量的时间;二是安装介质对复制速度的影响。
Kickstart是一个带有特定语法格式的自动应答文件,在安装操作系统之前客户端通过读取Kickstart配置文件来感知安装过程中的所有应答选项,并通过网络完成文件的复制。
cobbler
自动化部署系统Cobbler。它的核心机制依旧是Kickstart技术
第一,实现了统一大业,把过去零碎的组件进行了系统整合。<br>第二,封装了很多实用的组件功能,真正地解决了系统部署上的一些难题。<br>第三,管理的精细度增强了。
镜像复制
镜像复制方案倾向于制作一个涵盖所有场景需求的镜像文件,部署时推送这个镜像文件并解压到系统上,最后用脚本修改差异化配置。
镜像大法有一个致命的弱点—维护成本太高。
弊端
首先,镜像在复制过程中,有时难免会出现复制错误或者文件缺失的情况,这个问题却很难检查。<br>其次,做镜像也很痛苦。<br>最要命的是镜像的维护,任何一点点改动都涉及镜像文件的重新封装。
服务器管理
一种是使用IPMI来定义诸如带外管理地址、登录用户等初始化信息
另一种是使用厂商提供的私有化接口设置,诸如BIOS、电源策略、旦志告警等内容。
部署
手动部署一台服务器的操作系统的流程是怎样的。<br>第一步,完成设备上架和资产录入,资产录入需要自动化部署系统配合。<br>第二步,设备及配置识别,根据配置设计如何安装操作系统(包括安装系统类型、分<br>区、软件包等)。<br>第三步,服务器初始化设置,需要对带外管理卡进行设置。<br>第四步,安装操作系统,这是自动化部署的主要阶段。<br>第五步,交付系统并撰写实施环境说明,提交各种业务相关的信息。<br>当然,各个模块之间的调用需要通过Portal来完成。
命名规范
目录结构尽可能采取层级嵌套的方式,这符合现代系统管理的主流风格,比起把所有内容平铺到一个目录当中的做法,层级嵌套的效果显然要好很多。
每一个Profile都对应一个Kickstart,<br>每一个Kickstart对应一个执行脚本,执行脚本又对应若干二级脚本,而这些二级脚本才是<br>真正用来执行配置修改任务的。
VPC技术
通过VPC技术,用户可以将那些原本相互隔离的云,相互连接成一个整体,好像它们原本就同属一个云一样。而且用户可以完全自定义所有的网络配置和安全策略,构建属于自己的私有化云平台。
07.时间同步系统
如何实现时间同步
实现时间同步需要三个要素—标准时钟、传输手段和实现协议。标准时钟来自于原子钟。原子吸收或释放能量时会发出一种电磁波,由于电磁波极其稳定,所以利用这个特性制造出来的原子钟的计时是非常准确的。
利用卫星授时是实现全球范围的时钟精密同步的最好方式,卫星可在全球范围内使用超短波传播信号,大大提升了时钟同步的精度。
时间源的种类有很多,包括GPS、北斗等卫星授时、内置原子钟授时和恒温晶振,等等。
GPS授时
GPS系统包括卫星、地面监控系统和信号接收机三部分。GPS卫星不断地向外发射自身的星历参数和时间信息,信号接收机在收到信号后,根据三角公式计算就能得到接收机自身所在的位置。
PTP
时间同步协议除了我们熟知的NTP以外,还有一种叫作PTP。
PTP (Precision Time Protocol,精密时间协议)是一种用于网络时钟协议的解决方案。
PTP的时间精度远远优于NTP,时间精度能够达到亚微秒级。
使用硬件作为时间源服务器
使用硬件时间源服务器主要是从以下三个方面来考虑的:投时精度、可靠性、可维护性。
如果数据中心部署条件优良,且生产环境对于时间精确度的要求不是特别敏感,GPS和北斗二选一就可以了。如果情况相反、就一定要选用卫星+原子钟的模式。
平均故障间隔时间(Mean Time Between Failure,MTBF)是衡量一个产品可靠性的指标,单位是小时。这个数值越大,可靠性就越高。通常对于工控硬件设备的MTBF在50000~80000之间。
NTPD
构建时间同步系统,通常会采用多层NTP<br>Server的架构形式。硬件时间源作为一级授时,直接和从卫星获取时间。硬件时间源下联若干台服务器作为二级授时,为客户端提供时间同步服务。作为二级授时的服务器,内部部署使用的是ntpd。
让算机有两个时钟需要回步,一个是系统时钟、另外一个是硬件时钟,而ntpd默认只会同步系统时钟。
Dell、IBM、HP等一些国外的服务器,由于时区的默认设置问题,硬件时钟经常和系统时钟相差8小时。如果硬件时钟没有同步、当发生硬件故障时、硬件故障日志和系统日志的时间戳就不匹配,会给我们分析问题带来不小的麻烦。
chronyd
chronyd之所以在新的发行版中取代了ntpd,是因为chronyd具有如下ntpd所不具备的优势:
chronyd的守时效果更好,同步频率不需要像ntpd那么高。
chronyd因为守时效果好,使得它更加适应网络拥塞场景的出现。
chronyd通常可以更快地同步时钟并获取更好的时间精度。
chronyd能够迅速适应时钟速度的突然变化。
chronyd默认从不会发生跃迁事件。
chronyd可以在较大的范围内调整时钟速率(尤其是在虚拟机上)。
闰秒
定义
一个是基于地球自转的“世界时”(UT),还有一个是基于原子振荡周期的“原子时”(TAI)。“世界时”描述地球自转一圈是一天,但是地球自转不是绝对匀速的,所以不太可能恰好就是我们规定的86400s。
“原子时”和“世界时”之间存在着一定的偏差。如果放任不管,两者之间的差距会越拉越大。而闰秒的出现就是为了修复两者之间差距的。
1972年,出现了称为“协调世界时”(UTC)的折中时标。它以原子时的秒长为基础,在时刻上尽量接近世界时,确保它和世界时的偏差不超过0.9s。<br>原子时是我们的度量标准,世界时是我们历法的基准,而基于原子时的协调世界时是用来和世界时进行对比的,当两者之间的偏差超过1s时,就会触发闰秒事件。
危害
以增加闰秒来说,在整点时刻到来之前,UTC会以60s或者两个59s的形式出现,这会让系统内核或应用程序因为无法识别而彻底傻掉。
解决
亚马逊的解决方案是把多出来的这1s,在24小时的时间内消化掉。24小时总共是86400s,那么如果每秒都延长1/86400s,也就是0.000011574s。这么小的差距,不会对应用产生任何影响。
step
采取step的方式来处理闰秒,在闰秒来临时,关闭系统时间一秒,然后再次打开,借此方式来跳过闰秒。不过,这种做法对应用来说是不负责任的。因为在关闭系统时间的那一秒内所做的任何事都无法解释。
slew
它禁止内核自己去操作step,并且忽略对闰秒的处理。当闰秒出现之后,再通过slew模式慢慢地将时间差修正回来。
08.配置管理
学习有两种境界,一种是庖丁解牛的化境,另一种是化繁从简的炼境。
工具
ansible
AD-HOC
Ad-Hoc被称为Ansible的命令集,它采用模块调用的方式,可以迅速地完成一系列紧急的临时性任务
Playbook
相对于Shell脚本,Playbook的优势在于幂等性。如果Shell脚本自身的校验逻辑不够严谨,胡乱地重复执行有可能会出现意想不到的问题。Playbook则先天就自备检查功能。
Playbook使用的是YAML格式。YAML是依靠缩进来划分代码层次关系的,所以书写时对于缩进的要求非常严格。另处,缩进不支持Tab
Register
由于有些任务需要特定的条件来触发,在执行之前需要先检查条件是否具备。我们可以将检查结果先保存到Register,然后配合条件语句when 通过搜索Register中的关键字来决定下一步的动作。
动态定义inventory
在执行配置管理操作的时候,允许通过接口调用从CMDB中查询该项业务所涉及的所有主机,将全部地址列表返回生成一个新的Inventory文件
Puppet
Puppet有 modules和manifests两个空目录。modules顾名思义就是模块,可以把它理解成函数。Puppet把一组命令封装成一个module,通常一个module就是一个具体的执行任务。manifests里面存放的是配置文件,配置文件的扩展名是.pp。
saltstack
SaltStack 对此Ansible和Puppet来说有两个优势:第一,它不依赖于SSH服务,因此不受sudo、账户过期、并发性能和SSH服务通道失效等一系列的约束。第二,它的表达式简单便捷、清晰明了,既能快速地执行命令,也可以非常轻松地实现状态管理,SLS文件更加容易理解,其学习成本比起Playbook和Ruby来说要低得多。它的缺点在于并发瓶颈。SallStack作为小环境下的分治管理还是非常优秀的。
Ansibe的 Playbook 主打静态化的全量部署,SaltStack则用于执行平日里需要快速响应的任务。
09.文件共享服务
WebDAV
HITP协议本身并没有提供上传的接口,这就要借助WebDAV来实现上传功能。Web-
DAV(Web-based Distributed Authoring and Versioning)是一种基于HTTP1.1的通信协议,并在其基础之上添加了一些新的方法,使得应用程序可对HTTP Server直接进行读写,并支持文件锁和版本控制。
WebDAV on HTTPS
NFS
NFS是基于RPC的一个服务。RPC(Remote Procedure Call Protocol)是一种通过网络<br>从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。它跨越了传输层和应用层,在通信程序之间携带信息数据,使基于网络的应用程序开发变得更加容易。
NFSv4
最为显著的变化就是NFS v4集成了锁机制。锁机制对于文件请求访问来说是非常重要的。如果没有锁,当多个客户端同时对一个文件进行I/0操作时,会引发该文件数据块的损坏。在NFS v4之前,服务需要借助NLM(Network Lock Manager)的协助实现锁的操作。<br>早期的NFS v2和NFS v3支持UDP。<br>NFS v4明确要求传输层必须支持拥塞控制,所以UDP也不再被使用了。
SFTP
备份和容灾的区别
备份和容灾是两个完全不同的概念。备份的数据是静态的,数据可以是一份全备,也可以是一份全备加多份增量。而同步的数据是动态的,它会周期性地与生产端进行同步更新。如果在生产端上误删了数据,容灾端在随后一段时间内,同样也会将数据删除掉。容灾的目的是当生产端宕机无法对外提供服务和数据时,启动容灾端,恢复服务和绝大部分数据。虽然容灾的恢复效果弱于集群服务,但是它可以实现异地准冗余的手段,对于不适用于集群构建的SFTP服务来说是可行的。
10.硬件故障告警和维修
特点
硬件故障有两大特点。
第一,部件损坏的范围比较集中。
第二,故障发生的时间点相对集中。
硬件故障分为停机维修和非停机维修两种。除了更换硬盘和电源模块外,其他故障都需要停机操作。如果是停机维护,就要进行业务切换,进而影响到SLA指标。
告警方式
E-mail
Email 告警在少于3000节点时可以作为主要告警形式存在,在生产环境的建设初期。由于监控平台的不完善以及人员匮乏,它也是一种快速的替代方案。当生产规模超过3000节点时,它应该只作辅助告警。
SNMP
告警平台如能和CMDB实现联动,则可以在最短时间内开始故障处理
syslog
不必将所有内容都配置到告警范围内,否则会导致告警信息泛洪。
痛点
报修系统最终要解决三大难题—信息分拣、辅助录人和事件通告。<br>解决问题也不能完全依靠报修系统,流程化简也是一项同等重要的工作。<br>我们不要错误认为,设备只要没坏就不能停。因为你现在不停,早晚也得停。主动的人为干预远比将来发生故障所带来的影响要小得多。
信息分级
因为报修系统涉及的信息非常多,信息分级依旧是首要需求。顶级信息将以汇总的形<br>式来显示,应当只包含最基本的内容。<br>子项的展示形式有浮动窗口、弹出式窗口和折叠式几种。浮动窗口无法复制信息内容,而且它要求光标必须停靠在特定的位置上。也就是所谓的热区。
11.主机系统信息安全基础
密码学与数字证书
锁—是一种封印工具。
符一是一种身份的象征。
印—具有公信力和法律效力。
我的理解可以概括为如下八个字。
真实——指信息来源的真实性,也就是身份认证。
准确——指信息内容的准确性,防止他人篡改发送人原本要表达的意思。
机密—指保证信息内容不被第三方知晓。
保全一指对信息内容进行取证保全,防止干系人抵赖其曾经的行为。
数字证书
权威机构要发布一个可信的公钥,必须完成如下几件事。
妥善存储并管理用户的公钥及其相关信息;
将用户信息和公钥封装进一个容器;
在容器内写人颁发者信息并对所有内容进行签名。
这个权威机构被称为CA,而这个容器就叫做数字证书。
数字证书是“锁+符+印”的现代网络版。
运维红线举例
1.严禁私自分配资源或变更线上配置
2.严禁密码明文出现在命令行中
3.回退机制和灰度发布
4.严禁越权操作
除非 SSH的管理通道失效,严禁SE执行任何启停应用进程或重启、关闭主机的操作。
12.道与术
SA与SE
我们内部也管SA叫Suport All。
1.表和里的差别——技术深度
SA偏重于操作系统的使用、而SE则更注重系统内核和代码等深层次的东西。如果把操作系统比作汽车,那么SA就是驾驶员,而SE就是汽车设计师。
2.点和面的差别——驾驭能力
3.如何从传统运维向互联网行业转型
第一个是操作效率的能力。
第二个是横向扩容的能力。
三颗心
一个SE也要具有三题特别的心。
1.对生产系统要怀敬畏心
2.对业务需求要存谨慎心
3.对功名利禄要抱平常心
做事的四种态度
做牛马—把工作当负担,糊弄着做。
做任务一把工作当差事,尽职做。
做产品一把工作当作市场价值,用心去做。
做品牌—把工作当成文化传承,注魂去做。
改变自己
1.放大格局
2.无谓加班是无能的表现
3.自找苦吃
4.为自己打工