
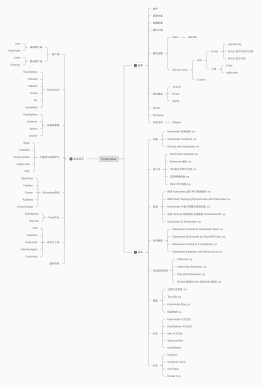
AI大模型应用工程化路线图
2026-01-07 17:14:26 3 举报AI智能生成
AI大模型应用工程化路线图
一图看懂AI
AI
大模型
模板推荐
作者其他创作
大纲/内容
1. 前置知识
编程语言
Python编程基础<br>
变量、数据类型、控制流语句、函数等基础语法
Anaconda、Jupyter、PyCharm 等开发环境的安装与配置
熟悉 Python 编程规范(如 PEP8),进行简单编程练习
Java编程基础
基础语法:变量、运算符、流程控制
面向对象编程:类与对象、封装&继承&多态、接口
集合、IO、多线程、StreamAPI
Go、C#、JavaScript、....
数学基础
高等数学
导数、偏导、梯度
线性代数
标量与向量、矩阵与张量、矩阵求导
概率与统计
概率分布
贝叶斯定理
似然函数
2-大模型应用基础
基础认知
AI与大模型的发展历程
从机器学习到深度学习的飞跃
深度学习的诞生与发展
大模型与通用人工智能
大模型的起源与发展
认知与解析、大模型与AGI关系、发展趋势
AI应用场景
自然语言处理-NLP
分词、词性标注、命名实体识别等NLP基础概念
文本分类、文本生成、问答系统、信息摘要、机器翻译
计算机视觉-CV
熟悉图像分类、目标检测、语义分割等CV基本概念
图像识别、视频分析
语音识别与合成
语音到文本、文本到语音
主流大模型的使用
国际知名
Meta:Llama系列
OpenAI:GPT系列
Google:Gemini
Anthropic:Claude系列
国产主流
深度求索:DeepSeek
阿里:Qwen系列
百度:文心大模型
智谱清言:GLM系列
主流大模型平台的功能特点、优势与适用场景
大模型的发展历程、关键推动因素与趋势
GPT为例
架构原理
Transformer架构讲解与动手实现
编码器 - 解码器结构
自注意力机制与多头注意力机制
大模型如何理解和表示单词
大模型如何理解并预测输入的内容
Transformer 变体之 Bert架构
使用上文与下文的双向预测模式 (类似于填空)
Transformer 变体之 GPT 架构
使用从前到后的单向预测模式 (类似于补全)
MoE模型<br>
MoE模型的工作原理
MoE模型的优点
MoE模型的应用
自然语言处理
计算机视觉
推荐系统
硬件基础
GPU加速原理<br>
GPU与CPU计算核心的区别对比<br>
CUDA核心/显存管理<br>
混合精度训练<br>
FP16/FP32混合使用<br>
提示词工程设计<br>
提示词工程基础<br>
Prompt基本概念、在大模型应用中的重要性<br>
Prompt 四要素:角色、目标、执行方案、输出格式<br>
Prompt设计的基本原则:简洁性、上下文与语境的设计、问题明确性、结构化与非结构化prompt<br>
Prompt调优与技巧<br>
常见的Prompt 工程设计策略
零样本提示(Zero-Shot)
少样本提示(Few-Shot)
链式思考(思维链COT)<br>
自我一致性(自洽性,Self-Consistency)<br>
思维树(Tree-of-thought,ToT)<br>
优化Prompt的输出效果<br>
调整Prompt中的语句顺序
指令和示例的数量与多样性
负面提示与约束
增强输出的精确度
高级Prompt工程技巧
指令模型 vs 推理模型的prompt的不同设计
复杂任务的多步骤Prompt设计
解构提示词对AI大模型反馈结果的影响
用 prompt 调优 prompt
Prompt攻击与防范
提示词注入
提示词防范<br>
项目实战<br>
案例:短剧脚本生成<br>
案例:网络爆款文案生成<br>
案例:数据库查询SQL语句生成<br>
案例:文本生成任务的Prompt设计(如编写文章、故事生成)<br>
案例:情感分析与文本分类的Prompt优化<br>
案例:复杂任务的多步骤Prompt设计(如数据分析报告生成)<br>
3-大模型应用实战之主流开发框架<br>
LangChain框架<br>
LangChain框架简介<br>
构建大模型应用的完整流程:大模型交互、数据整合、应用部署<br>
LangChain的安装<br>
调用大模型三要素:base_url、api_key、model_name<br>
LangChain核心组件<br>
模型IO操作<br>
几种不同的Message
invoke、stream、batch、ainvoke等<br>
Prompt Template<br>
Output Parsers<br>
FunctionCaling
链架构:Chains / LCEL<br>
Chains的设计理念<br>
传统的Chain<br>
SequentialChain
RouterChain
Chains功能实战<br>
Memory记忆功能<br>
不借助LangChain,如何实现记忆功能
Memory模块的设计理念<br>
如何自定义Memory模块<br>
spacy工具安装<br>
内置的Memory模块<br>
智能体Agents<br>
Agent架构设计理念的背景<br>
基于LangChain的Agent抽象<br>
自定义基于ReAct范式的Agents<br>
使用LangChain定义的ReAct策略<br>
Retrieval
RAG架构<br>
Source 与 data loaders
Text Splitters
Text embedding models
vector store
项目实战<br>
案例1:LangChain构建智能问答系统<br>
案例2:LangChain实现文档摘要生成<br>
案例3:LangChain实现AI销售助手<br>
LangChain4J框架<br>
LangChain4J框架简介<br>
LangChain4J的定位<br>
核心特性:低代码API、内存优化、本地模型支持<br>
安装:Maven/Gradle依赖配置<br>
核心组件<br>
LangChain4J基础架构<br>
LLM接口:支持 OpenAI、DeepSeek、ZhiPu AI、Anthropic<br>
内存管理:维护对话上下文(Memory),支持短期 / 长期记忆<br>
提示模板:动态生成 prompt(PromptTemplate),支持变量替换和格式控制<br>
链(Chain):串联多个组件(如 LLM + 数据库查询),实现复杂逻辑<br>
智能体(Agent):根据用户输入动态选择工具(API / 数据库)执行任务<br>
聊天与语言模型<br>
LLM API类型:LanguageModel、ChatLanguageModel<br>
ChatLanguageModel核心方法<br>
消息类型:UserMessage、AiMessage、SystemMessage、ToolExecutionResultMessage、CustomMessage<br>
ChatMemory组件<br>
ChatMemory的作用:消息管理、持久化存储、特殊消息处理<br>
核心实现与特性<br>
AI Services的使用<br>
AI Services的定位与优势<br>
注解支持:@SystemMessage、@UserMessage<br>
RAG
什么是RAG<br>
RAG核心流程:索引阶段、检索阶段<br>
RAG类型:EasyRAG、NaiveRAG、AdvancedRAG<br>
核心API与组件:Document、Metadata、Document Loader、Embedding Model等<br>
与SpringBoot3集成<br>
项目实战<br>
案例1:本地知识库问答系统(RAG+ChromaDB)<br>
案例2:自动化报表分析(代理+表格工具)<br>
案例3:多模态AI助手(集成TTS/OCR)<br>
SpringAI & SpringAI Alibaba框架<br>
Spring AI框架简介<br>
Spring AI的定位<br>
核心优势<br>
安装与配置<br>
核心组件<br>
模型交互(Model I/O)<br>
统一接口设计:AiClient与AiStreamClient<br>
多模型支持:OpenAI、HuggingFace、本地模型集成<br>
提示工程:动态提示模板(PromptTemplate)与输出解析(OutputParser)<br>
数据整合(Retrieval)<br>
向量数据库集成:RedisVectorStore、PgVector<br>
文档处理链:文本分块(TextSplitter)、嵌入模型(EmbeddingModel)<br>
RAG实现:检索器(Retriever)与生成器组合<br>
链式执行(Chains)<br>
链式抽象:Chain接口与SequentialChain<br>
路由链(RouterChain):多任务动态路由<br>
实战:文档总结链、问答链构建<br>
代理(Agents)<br>
代理机制:基于ReAct的决策框架<br>
工具集成:自定义工具(如数据库查询、API调用)<br>
案例:销售顾问代理实现<br>
记忆管理(Memory)<br>
对话状态存储:ChatMemory接口<br>
存储后端:Redis、In-Memory配置<br>
项目实战<br>
案例1:基于Spring AI的智能客服系统(集成RAG)<br>
案例2:文档自动摘要生成(链式调用+文本分割)<br>
案例3:企业级RAG问答系统(向量库+代理)<br>
4-大模型应用实战之RAG开发<br>
EmbeddingModels嵌入模型<br>
嵌入表示的基本概念与工作原理<br>
常见的嵌入技术<br>
词嵌入:Word2Vec、GloVe、FastText等经典方法<br>
文本嵌入:BERT、GPT等预训练模型的嵌入<br>
图像和音频的嵌入表示<br>
特征嵌入:如何将结构化数据转换为嵌入表示<br>
VectorStore向量存储<br>
向量数据库介绍<br>
如何存储和检索嵌入向量<br>
常见的向量数据库:Milvus、Chroma、Pinecone、FAISS等<br>
向量数据库与传统数据库的区别与优劣对比<br>
向量数据库的核心操作<br>
Add添加数据<br>
Query查询数据<br>
Update/Delete管理数据<br>
使用向量数据库进行相似性检索<br>
向量存储应用<br>
文本相似度搜索:基于向量的文档匹配
图像识别与检索:特征向量提取与匹配<br>
推荐系统:基于用户与物品的向量表示<br>
RAG 工程化
RAG技术概述<br>
LLM面临的主要问题<br>
信息偏差/幻觉、知识更新滞后性、内容不可追溯<br>
领域专业知识能力欠缺、长文本处理能力较弱<br>
什么是RAG技术?<br>
RAG技术优势<br>
外部知识的利用、生成内容的准确性<br>
数据及时更新、模型的可解释性<br>
高度定制能力、减少成本<br>
RAG的核心原理与工作流程解析<br>
RAG应用流程<br>
数据准备阶段<br>
数据提取<br>
文本分割<br>
向量化 (Embedding)<br>
数据入库<br>
检索生成阶段
问题向量化<br>
数据检索<br>
注入Prompt<br>
LLM生成答案<br>
RAG技术关键环节<br>
数据检索<br>
Prompt设计<br>
RAG技术迭代<br>
NaiveRAG→AdvancedRAG→ModularRAG<br>
GraphRAG
知识图谱<br>
GraphRAG原理与工作流<br>
AgenticRAG
RAG使用效果评估<br>
质量指标<br>
上下文相关性、答案忠诚度、答案相关性<br>
能力指标<br>
噪声的鲁棒性、负面信息的排除能力、面对假设情况的健壮性<br>
评估工具<br>
RAGS评估、TruLens评估<br>
RAG在AI对话系统中的应用<br>
使用RAG提升对话系统的表现与智能化<br>
结合检索与生成的实际案例分析<br>
项目实战<br>
案例1:QAnything+Chroma+LLM构建本地私有知识库问答系统<br>
案例2:Dify + DeepSeek快速构建企业私有知识库/客服助手<br>
案例3:RAGFlow+DeepSeek构建企业级知识库<br>
5-大模型应用实战之Agent开发<br>
认识智能体<br>
智能体的定义与作用<br>
智能体的基本架构与功能<br>
规划(Planning)<br>
记忆(Memory)<br>
工具使用(Tools)
执行(Action)<br>
工具调用:Funcation Calling<br>
FunctionCalling的概念与应用<br>
Function Calling简单理解<br>
FunctionCalling的实现过程<br>
跨系统与跨语言的FunctionCalling<br>
FunctionCalling支持的国产模型介绍<br>
如何实现不同模型、不同系统间的功能调用<br>
Function Calling的优化<br>
提升FunctionCalling的性能与稳定性<br>
设计高效的FunctionCalling机制<br>
多Function Calling的使用<br>
工作流Workflow的搭建与使用<br>
为什么我们需要工作流?<br>
大模型应用工作流的关键要素解析<br>
Agently Workflow的工作流要素图示<br>
项目实战<br>
案例1:一键生成学术论文<br>
案例2:一键生成爆款视频<br>
Agent系统<br>
什么是多Agent?<br>
AutoGen框架<br>
MetaGPT框架<br>
Multi-Agent会话
LangGraph框架<br>
LangGraph基础使用<br>
LangChain与langGraph的区别<br>
LangGraph对象:图(节点、边、状态)的定义与使用<br>
LangGraph进阶:检查点(记忆功能)与中断点(手动介入)<br>
LangGraph工具:搜索引擎<br>
LangGraph 调试:结合LangSmith查看Agent调用栈<br>
LangGraph实践与延展<br>
LangGraph Agent架构<br>
基于LangGraph构建生产级的AI Agent<br>
基于LangGraph构建Multi Agent(多智能体)<br>
项目实战<br>
案例1:基于LangGraph实现多轮对话聊天机器人<br>
案例2:基于LangGraph构建企业级复杂多代理应用<br>
项目实战<br>
案例1:基于Dify快速构建智能体应用<br>
案例2:数据分析助手<br>
案例3:携程APP 智能体<br>
案例4:基于LangChain Agent构建下一代AI助手<br>
6-大模型微调<br>
模型微调基础<br>
模型微调的概念<br>
模型微调的概念与意义<br>
微调和 RAG 的关系<br>
不同场景下微调的必要性<br>
什么是训练/预训练/微调/轻量化微调<br>
数据工程<br>
数据采集与清洗<br>
数据标注与增强<br>
数据集划分<br>
微调的核心流程<br>
数据准备与清洗:选择高质量的数据集<br>
微调技术要点:设置超参数、选择合适的训练方法<br>
模型评估与验证:确保微调后模型的效果<br>
微调框架的选择<br>
pyTorch框架<br>
张量的创建、索引、运算等操作<br>
搭建神经网络,定义模型结构、前向传播、反向传播的流程<br>
案例:基于 PyTorch 的模型构建与训练之手写数字识别<br>
HuggingFace Transformers工具<br>
unsloth 框架<br>
unsloth 的开箱可用与高度可定制化<br>
LLaMA-Factory 框架<br>
DeepSpeed
大模型训练技术<br>
分布式训练<br>
数据并行与模型并行<br>
梯度累积与同步<br>
DeepSeed分布式训练/Llama Factory/Xtuner<br>
混合精度训练<br>
FP32与FP16混合使用<br>
动态损失缩放<br>
模型压缩与加速<br>
剪枝技术<br>
量化技术<br>
知识蒸馏<br>
微调技术与应用<br>
微调策略<br>
基于预训练模型的微调<br>
基于特定数据集进行模型微调,包括数据准备、参数设置、训练过程<br>
解决微调过程中过拟合、训练不收敛等常见问题的方法<br>
轻量化微调技术详解<br>
Prompt Tuning、P-Tuning、Prefix Tuning<br>
LoRA、QLoRA<br>
大模型微调实战篇<br>
案例1:基于 LoRA 微调Qwen2 7B
案例2:基于 QLoRA 微调 Llama3 8B
案例3:基于 QLoRA 微调GLM4 9B<br>
Huggingface模块开发实战<br>
Huggingface 的安装和开发流程<br>
掌握Huggingface库中各种API的调用<br>
Huggingface工具集:批量编码,Loadding,评价指标,管道等<br>
Transformer加载模型、数据集合预处理<br>
项目实战<br>
案例1:动手微调一个GPT<br>
模型加载<br>
数据加载<br>
训练器<br>
案例2:医疗问诊助手<br>
基础应用:理解并应用大模型的微调与预训练<br>
核心实操:定制化微调和预训练模型<br>
优化技巧:提升微调与预训练的效率与效果<br>
DeepSeek深度解析<br>
DeepSeek的基础架构MoE深度解析<br>
DeepSeek核心优势<br>
DeepSeek-V3的关键技术解析<br>
DeepSeek-R1的关键技术解析<br>
Deepseek中的创新点分析<br>
模型架构<br>
训练数据优势<br>
通俗理解模型蒸馏技术以及实现原理<br>
蒸馏模型基本概述<br>
蒸馏模型的变体与特征<br>
详解Deepseek-r1的四阶段训练流程<br>
训练目标<br>
数据处理方式<br>
模型参数调整策略<br>
7-大模型实战工具<br>
Ollama工具<br>
Ollama定义与安装<br>
如何调用私有大模型<br>
云端部署(AWS、阿里云)、本地部署等模型部署流程与方法
Ollama Java or python Rest API-与模型对话<br>
Dify Al 平台<br>
Dify 定义与搭建<br>
Dify本地部署与服务器部署<br>
Dify 工作流构建以及工具调用<br>
Dify导入外部知识库<br>
项目实战<br>
案例:如何搭建Al Agent<br>
案例:搭建智能AI客服<br>
Claude Al 工具<br>
Claude注册和使用<br>
Claude 模型与Claude API Key
Claude Function Calling原理与实现<br>
实战项目-天气查询<br>
Anthropic MCP<br>
FunctionCalling vs MCP<br>
Function calling 是如何工作的?<br>
Function Calling企业级应用的关注点<br>
如何使用FunctionCalling<br>
MCP 概念、原理剖析与C/S架构
案例:多种MCP Servers部署与测试<br>
案例:自定义MCP<br>
AI代码编程工具-Cursor Al<br>
Cursor的使用技巧<br>
Cursor的调试技巧<br>
快速开发自己的项目<br>
Coze(扣子)平台<br>
Coze的概述与注册<br>
设置提示词<br>
如何使用工作流<br>
创建自己的插件<br>
添加知识库:文本、表格、图片<br>
创建并使用数据库<br>
AIGC生成式大模型各类工具<br>
生成简历,写小红书文案项目<br>
Kimi+GPT4+文心一言+Gemini大模型实操对比<br>
大模型辅导学生做数学题实操项目<br>
小红书创造文案和抖音脚本创作和分镜头实操项目<br>
短片小说创作爆款微头条项目<br>
大模型进行AI画图<br>
...<br>
8-大模型项目实战<br>
GPT大型智能翻译助手项目<br>
大模型企业级方案设计<br>
基于GPT-4o大模型+Langchain中间件<br>
加载数据模块,AI模型加载模块,输出数据模块,可视化界面模块等<br>
基于Gradio的Web界面,支持PDF,Word,MarkDown等各种文件格式<br>
基于Transformer的NLP项目<br>
Transformer模型,以及搭建机器翻译系统<br>
Encoder-Decoder 架构与缩放点击注意力,实时语音和文字翻译模型<br>
基于RAG贝壳网智能客服问答系统<br>
GLM4-9B + Langchain中间件<br>
Vector数据,相似检索<br>
数据Split之后通过Embedding向量化<br>
Gradia的UI界面,FastAPl接口,uvicorn服务器<br>
京东客户购买意向预测项目<br>
数据清洗,数据挖掘,数据探索,构建user信息<br>
特征工程:数据处理维度,数据基本特征,用户类别,行为特征处理,构建数据集<br>
Xsboots建模:数据加载,模型训练,特征重要性查看,算法预测验证数据,验证数据模型评估,测试数据模型评估<br>
TEXT2SQL+Qwen3大模型项目实战<br>
TEXT2SQL项目介绍<br>
数据库连接以及langchain自带工具集学习<br>
核心工作流开发:工作流规划-定义异步工作流-异步执行工作流<br>
如何私有化部署最新Qwen3<br>
MCP服务端开发<br>
9. 前沿:多模态
多模态理论基础<br>
多模态的最新进展<br>
模态与多模态的概念<br>
为什么需要多模态?通往AGI的必经之路<br>
多模态技术应用领域<br>
人机交互
多模态交互界面设计<br>
多模态情感计算<br>
智能安防<br>
多模态身份认证<br>
智能视频监控<br>
医疗健康<br>
远程医疗咨询<br>
辅助诊断与治疗<br>
智能教育<br>
多模态学习资源<br>
智能教学系统<br>
大模型与计算机视觉<br>
安防视觉识别模型原理<br>
零件缺陷检测模型原理<br>
医疗诊断识别模型原理<br>
无人驾驶视觉模型原理<br>
图像生成技术概述<br>
扩散模型—Diffusion Model<br>
基于Diffusion扩散模型的多模态模型<br>
稳定扩散模型一StableDiffusion<br>
多模态机器学习与典型任务<br>
跨模态预训练<br>
Language-Audio / Vision-Audio / Vision-Language<br>
AffectComputing情感计算<br>
多模态技术未来发展趋势<br>
多模态的微调与优化<br>
多模态模型的微调<br>
迁移学习<br>
零样本学习<br>
多模态模型的优化<br>
剪枝<br>
量化
蒸馏
压缩
多模态模型的部署<br>
本地私有化部署图文描述模型<br>
本地私有化部署文生视频模型<br>
选择模型打包格式<br>
硬件加速方案<br>
项目实战<br>
案例1:基于 BLIP 的图生文<br>
案例2:基于StableDiffusion的文生图<br>
案例3:基于Llama-Vision的视觉问答<br>
案例4:短视频脚本生成(GPT-4o+多模态提示)<br>
案例5:医疗影像报告生成(BLIP+LLM)<br>
10. 储备:系统开发
容器化技术:Docker、K8S<br>
云计算平台:AWS、阿里云<br>
微服务架构设计<br>
11. 进阶:AI算法
Python数据分析<br>
NumPy、Pandas、Matplotlib<br>
机器学习<br>
概念与工具<br>
特征工程<br>
模型评估&模型选择<br>
监督学习算法<br>
线性回归<br>
逻辑回归<br>
KNN近邻算法<br>
其它监督学习算法<br>
朴素贝叶斯<br>
决策树<br>
支持向量机<br>
集成学习<br>
无监督学习<br>
聚类<br>
K-means<br>
高斯混合聚类<br>
密度聚类<br>
层次聚类<br>
谱聚类<br>
降维<br>
主成分分析<br>
奇异值分解<br>
深度学习、神经网络与PyTorch开发<br>
神经网络基础<br>
传统机器学习与深度学习的发展<br>
神经网络的定义和分类<br>
神经网络基本概念<br>
损失函数<br>
数值微分<br>
梯度计算<br>
随机梯度下降法<br>
PyTorch
PyTorch的安装<br>
PyTorch中的张量<br>
张量创建与数值计算<br>
张量类型转换<br>
张量拼接<br>
张量索引<br>
运算函数与自动微分模块<br>
模型定义与保存加载<br>
利用PyTorch进行深度学习<br>
常见问题分析
深度学习常见模型1:卷积神经网络CNN<br>
图像特征提取<br>
目标检测<br>
深度学习常见模型2:循环神经网络RNN<br>
时间序列预测<br>
自然语言处理NLP<br>
NLP自然语言处理<br>
NLP的概述<br>
NLP的基本概念<br>
NLP的两大核心任务:NLU/NLI、NLG<br>
NLP 的工作原理<br>
文本预处理<br>
特征提取<br>
文本分析<br>
模型训练<br>
文本是如何转换为数据的<br>
语言模型 (N-Gram模型)<br>
分词 - Tokenization
Word2Vec 模型<br>
打造能识别文本情感的模型
详解语言模型与注意力机制
大模型关键技术解析<br>
预训练<br>
SFT (Supervised Fine-Tunning)
RLHF(Reinforcement Learning from Human Feedback)<br>
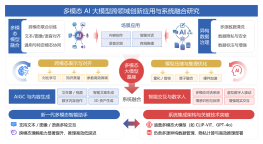
收藏
立即使用

收藏
立即使用
职业:开发1
Collect
Get Started
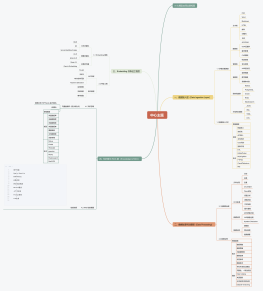
Collect
Get Started

Collect
Get Started
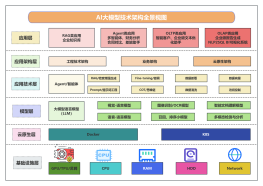
Collect
Get Started
评论
0 条评论
下一页

