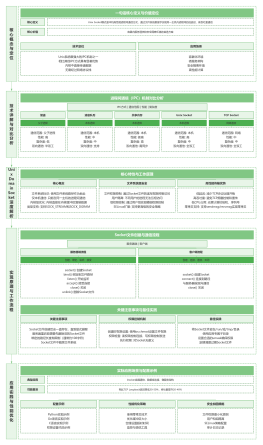
一致性<br>
zookeeper中保证数据一致性用的是ZAB协议
顺序一致性<br>
原子性<br>
系统视图唯一性<br>
持久性<br>
及时性<br>
zk一致性保证的是<br>
写请求是线性一致性的,读不是
任何给定的client操作的执行顺序是<font color="#a23735">由client来决定的</font>,其称之为FIFO Client Order
工作方式<br>
FIFO client order会应用于<font color="#a23735">单个client的所有请求</font>
zk没有保证<b><font color="#a23735">跨客户端</font></b>的强一致性<br>
两个情况<br>
leader执行commit了,还没来得及给follower发送commit的时候,leader宕机了
leader的事务性请求已经在<b>部分节点(不是全部)</b>应用了,这个时候leader挂掉了<br>
特性<br>
Zab 协议需要确保那些已经在 Leader 服务器上提交(Commit)的事务最终被所有的服务器提交。<br>
Zab 协议需要确保丢弃那些只在 Leader 上被提出而没有被提交的事务。
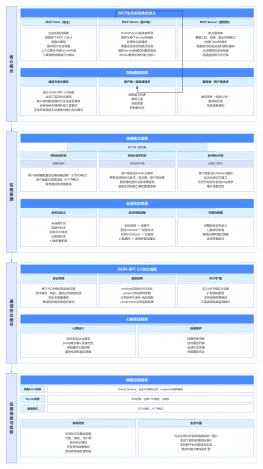
Zab协议核心<br>
定义了事务请求的处理方式
1、<font color="#f44336">所有的事务请求必须由一个全局唯一的服务器来协调处理</font>,这样的服务器被叫做<b><font color="#f44336">Leader</font></b>服务器。其他剩余的服务器则是<b><font color="#f44336">Follower</font></b>服务器。<br>
2、<b><font color="#f44336">Leader服务器 </font></b>负<b>责将一个客户端事务请求,转换成一个事务Proposal</b>,<b>并将该 Proposal 分发给集群中所有的 Follower 服务器</b>,也就是向所有 Follower 节点发送数据广播请求(或数据复制)<br>
顺序一致性<br>
问题<br>
ZooKeeper 集群的写入是由 Leader 结点协调的,真实场景下写入会有一定的并发量,那 Zab 协议的两阶段提交是如何保证事务严格按顺序生效的
Leader 是如何判断当前 ZXID 之前是否还有未提交提案的
leader顺序性
处理队列(包括读写)+ 写等待<br>
follower顺序性<br>
<b><font color="#f44336">提案下发阶段</font></b>:leader下发提案到follower时
对比新提案的 ZXID 与自身最新 ZXID 是否相差“1”,来保证事务顺序生效
<b><font color="#f44336">提交阶段:</font></b>leader下发commit时<br>
通过对比commit request的zxid和<font color="#a23735">pendingTxns的zxid</font>
步骤<br>
总之:<font color="#f44336"><b>Follower通过队列和zxid等顺序标识保证请求的顺序处理,一言不合就会退出或者重新同步Leader</b></font>。
client回调顺序性<br>
按序出队
比较xzid
zookeeper如何保证半数提交后剩下的节点上最新的数据<br>
剩下的节点,会进行版本比对,发现版本不一致的话,会更新节点的数据(退出重新同步)
崩溃恢复模式
ZAB的保证
Zab 协议需要确保那些已经在 Leader 服务器上提交(Commit)的事务最终被所有的服务器提交。<br>
Zab 协议需要确保丢弃那些只在 Leader 上被提出而没有被提交的事务。
针对以上的两个要求,在进行 Leader 选举时,<b><font color="#f44336">只需要选举出集群中 ZXID 最大的事务 Proposal 即可</font></b>,这样就可以省去 Leader 服务器检查 Proposal 的提交和丢弃工作了。<font color="#f44336"><b>因为 Leader 服务器的事务是最大的,一切以 Leader 服务器的数据为标准即可</b></font>。
流程<br>
恢复(Recovery)<br>
数据同步策略<br>
SNAP<br>
DIFF<br>
TRUNC<br>
TRUNC+DIFF
脑裂问题<br>
避免脑裂现象的限制条件<br>
集群中存活的节点数必须要超过总节点数的半数才能继续提供服务
zk推荐奇数台集群搭建<br>
原因<br>
发生网络分层时,不会发生两层节点数相同,集群无法服务的现象<br>
与偶数个节点比,容灾能力一样但更节省资源<br>
最小节点数quorum小,响应速度快<br>
问题<br>
那些没有收到commit消息的follower怎么最终和leader数据保持一致<br>
leader执行commit了,还没来得及给follower发送commit的时候,leader宕机了,这个时候如何保证数据一致性<br>
客户端把消息写到leader了,但是leader还没发送proposal消息给其他节点,这个时候leader宕机了,leader宕机后恢复的时候此消息又该如何处理<br>
<b><font color="#f44336">同一个客户端</font></b>,先发出写请求,leader将写请求事务广播给follow,如果半数follow成功,但是发出请求的follow没有成功,按照半数即成功的原理,leader会返回写操作成功,此时该客户端再读取数据,导致读取到的是旧的值,是不是不符合同一个session写后读的保证?
多个客户端读到的数据不一致<br>
ZooKeeper 负载均衡和 Nginx 负载均衡有什么区别<br>
集群最少要几台机器,集群规则是怎样的?集群中有 3 台服务器,其中一个节点宕机,这个时候 Zookeeper 还可以使用吗?
集群支持动态添加机器吗<br>
Zookeeper对节点的watch监听通知是永久的吗?为什么不是永久的