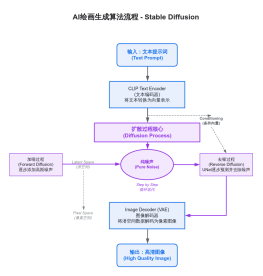
基础
2022 年 2 ⽉,Disco Diffusion 横空出世<br>2022 年 4 ⽉,DALL·E 2 与 Midjourney 相继内测<br>2022 年 5 ⽉,Google 发布 Imagen<br>2022 年 7 ⽉,Stable Diffusion 重磅来袭
https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb#scrollTo=SetupTop
Disco Diffusion
DALL·E 2
https://openai.com/dall-e-2/
Midjourney
https://discord.gg/midjourney
部署
1 windows系统请采用秋叶一键部署包安装,一键部署包作者和链接如下:
https://www.bilibili.com/video/BV1iM4y1y7oA/?share_source=copy_web&vd_source=43cc0d3785a52cc3923cbf16ae943cce
2 Mac系统安装过程请参考直播回放(行动营课程直播回放 / B站极客时间官方账号), 课程中会采用视频方式逐步讲解,带大家安装好sd,此处仅为用户尽早体验sd基本安装步骤如下:
(1) brew命令https://brew.sh
(2)brew install cmake protobuff rust python@3.10 git wget (阿里云)
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cpu
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
git clone https://gitee.com/wilsonyin/stable-diffusion-webui
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install gfpgan
webui.sh
使用
文生图
Seed 决定了画⾯内容
CFG Scale 决定了画家⾃由度
步⻓影响时间与效果,通常 30 够了
⽂⽣图-CFG
CFG 2 - 6:⼴告素材,但可能不会按照提示操作
CFG 7 - 10:建议⽤于⼤多数提示,好;创造⼒和引导式⼀代之间的平衡
CFG 10 - 15:当您确定提示是好,⾜够具体
CFG 16 - 20:⼀般不推荐,除⾮提示⾮常详细
⽂⽣图-采样器
⽤于在⽣成过程中对图像进⾏去噪的⽅法 <br>它们需要不同的持续时间和不同的数量
图⽣图
CFG Scale
Denoising strength
图扩展图
根据提示词 + MASK + 图⽚⽣成图⽚
提示词
语义 Tag<br>关键词逗号分隔
混合<br>关键词 | 分隔
权重<br>(提示词:权重数值)<br><1 减弱 <br>>1 加强
交替<br>[轮流使⽤关键词]<br>开始 是猫 <br>后⾯ 像狗
强化效果<br>[强化关键词]<br>best quality, <br>masterpiece,
反向词效果<br>[去掉不要的]<br>nsfw, bad face…
控制类<br>[强化形态]<br>full body shot(全身照)
控制类<br>[强化形态]<br>cowboy shot(半身照)
控制类
光线 <br>cinematic lighting (电影光) <br>dynamic lighting (动感光)<br>视线 <br>looking at viewer <br>looking at another <br>looking away <br>looking back <br>looking up<br>画⻛ <br>sketch<br>视⻆ <br>dynamic angle <br>from above <br>from below <br>wide shot
玩法
1.你想要⼀张照⽚还是⼀幅画? <br>2. 照⽚的主题是什么?⼈?是动物还是⻛景? <br>3. 你想添加哪些详细信息? <br>‣ 特殊照明:柔和、环境、环形灯、霓虹灯 <br>‣ 环境:室内、室外、⽔下、太空 <br>‣ 配⾊⽅案:充满活⼒、深⾊、柔和 <br>‣ 视⻆:前、头顶 <br>‣ 背景:纯⾊、 星云、森林 <br>4. 以特定的艺术⻛格?3D 渲染 <br>5. 特定照⽚类型?微距、⻓焦
现实⽣活中⼥孩的照⽚,电影照明,从窗户偷看,鲜艳的⾊彩,散景,电影海报⻛格<br>Photo of real life girl, cinematic lighting, peeking from window, vibrant colors, <br>bokeh, movie poster style
大模型玩法
模型常⻅格式<br>(diffusers 格式)
sd 各个部分 (unet,vae-变分⾃编码器,<br>clip-⽂本编码器) <br>训练好的权重 (⼀般是 bin 格式) <br>scheduler (调度算法) <br>tokenizer (分词器)
模型常⻅格式<br>(Safetensors 格式)<br>Hugging Face 推出⾃⼰的储存格式<br>⽐ ckpt 格式加载速度更快、更安全
模型搜索<br>(civitai)<br>https://civitai.com/
模型特点<br>(novelai)<br>⼆次元模型,来⾃于 novelai 变种
https://civitai.com/models/66/anything-v3
模型特点<br>(Guofeng3)<br>中国华丽古⻛⻛格模型, <br>也可以说是⼀个古⻛游戏⻆⾊模型, <br>具有 2.5D 的质感。
子主题
https://civitai.com/models/10415/guofeng3
模型特点<br>(dreamlike)<br>逼真的 mid ⻛格
https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0
模型特点<br>(protogen)<br>真⼈⻛格
https://civitai.com/models/3666/protogen-x34-photorealism-official-release
模型转换<br>FP32:单精度浮点数 <br>FP16:半精度浮点数 <br>BF16:(Brain Float16) 是 FP32 尾数截断
Model Converter
模型转换<br>修剪<br>⽤来估计变量的局部均值
修剪<br>⽤来估计变量的局部均值
如果您在训练时将 EMA 设置为“false”,它会根据历史中提取数据。这有利于多样性。
如果你在训练时将 EMA 设置为“真”,它会根据最近的历史记录⽽不是所有历史记录。适合制作⾃定义模型。
模型融合<br>独特的⻛格和擅⻓的⽅⾯<br>VAE
模型融合<br>⼈像 + ⼆次元
SD 可控使用
WebUI 扩展安装⽅法
1. Open "Extensions" tab. <br>2. Open "Install from URL" tab in <br>the tab. <br>3. Enter URL of this repo to "URL <br>for extension's git repository". <br>4. Press "Install" button. <br>5. Reload/Restart Web UI.
精准可控(提示词)<br>提示词的强化<br>反向提示词的强化
精准可控(区域)<br>Latent Couple
精准可控(区域)<br>多⼈合照<br>Latent couple 与 Composable LoRA(后⾯讲到)
https://github.com/opparco/stable-diffusion-webui-composable-lora
精准可控(区域)
笔画区域 控制
精准可控(动画)<br>SD 可控使⽤⼀<br>a beautiful forest by Asher Brown Durand, trending on Artstation
https://github.com/deforum-art/deforum-for-automatic1111-webui
精准可控(ChatGPT)<br>⽣成⼀致性图像<br>Prompt: a forest path with trees <br>ChatGPT: Describe 5 unique fantasy settings <br>given the prompt "{prompt}" with 4 keywords <br>per item
https://github.com/hallatore/stable-diffusion-webui-chatgpt-utilities
子主题
ControlNet
在⽂本描述之外添加⼀些额外条件来控制扩散模型 <br>实现了⼈体姿势/图像边缘/深度图/语义⾊块图/法线图等多种⽅式对⽣成的图像
https://github.com/Mikubill/sd-webui-controlnet
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
子主题
子主题
M-LSD<br>room
HED Boundary
Scribbles
Human Pose
Segmentation
Depth
Normal
多个 control net
子主题
子主题
真⼈⼆次元化<br>Canny + ⼆次元⼤模型
https://stablediffusionweb.com/ControlNet#demo
SD 微调模型
如何让画⾯中的⼈物或事物变成⾃⼰<br>如何让画⾯⻛格变成特定效果
在较⼩的数据集上⽣成准确的模型,其训练成本⽐训练原始模型所涉及的成本低得多。 <br>通过微调学习,你可以在你⾃⼰的数据集上微调稳定的扩散模型。
分解为⼏个关键模型
1. 将输⼊提示投影到潜在空间的⽂本编码器。(与图像关联的标题称为“提示”)<br>2. ⼀种变分⾃动编码器 (VAE),它将输⼊图像投影到图像向量空间的潜在空间。<br>3. 改进潜在向量并产⽣另⼀个潜在向量的扩散模型,以编码⽂本提示为条件。<br>4. 给定扩散模型的潜在向量⽣成图像的解码器。
1. ⽂本编码器将输⼊⽂本提示投影到潜在空间。<br>2. VAE 的图像编码器部分将输⼊图像投影到潜在空间。<br>3. 对于给定的时间步⻓,将少量噪声添加到图像潜在向量中。<br>4. 扩散模型使⽤来⾃这两个空间的潜在向量以及时间步⻓嵌⼊来预测添加到图像潜在的噪声。<br>5. 计算预测噪声和步骤 3 中添加的原始噪声之间的重建损失。<br>6. 使⽤梯度下降对扩散模型参数进⾏优化。<br>在微调期间仅更新扩散模型参数,⽽(预训练的)⽂本和图像编码器保持冻结状态。
Textual Inversion
Hypernetworks
Dreambooth
LoRA
Embeddings 及 hypernetwork 使用
https://textual-inversion.github.io/
允许你在⾃⼰的图⽚上训练神经⽹络的⼀⼩部分,并在⽣成新图⽚时使⽤结果。 <br>是你训练的神经⽹络的⼀⼩部分。
Textual Inversion Embeddings <br>训练<br>Initialization text<br>指定图像特征的初始化⽂本<br>在 Initialization ⽂本中写上你想学习的标签<br>Pre token<br>⽤于嵌⼊的每个标记的⼤⼩<br>假设你指定了⼀个初始⽂本“tree”,其中包含⼀个名为“zzzzhello”的向量(⼀个标记)嵌⼊。 <br>在不使⽤提示“a zzzzhello by monet”的情况下使⽤它给出与“a tree by monet”相同的输出。
Textual Inversion Embeddings <br>训练<br>Embedding:选择你想学习的 Embedding<br>Learning rate:学习速度(将值设置得太⾼会破坏嵌⼊)<br>如果你在训练信息⽂本框中看到“Loss: nan”,则表示训练失败并且嵌⼊已死<br>Batch size<br>⽤于⼀次学习的图像数量。增加它会使⽤更多 VRAM 并减慢<br>计算速度,但会提⾼准确性。<br>Dataset directory<br>包含⽤于训练的图像的⽬录
训练<br>MaxStep<br>完成这么多步数后,训练将停⽌
特点<br>模型⽂件⼩,~30KB<br>通常不能捕获物品细节,擅⻓⻛格转换<br>可在 Prompt 中同时使⽤多个 Embeddings
Textual Inversion Embeddings
训练过程差不多<br>唯⼀的要求是使⽤⾮常⾮常低的学习率, <br>⽐如 0.000005 或 0.0000005。
Hypernetwork
Hypernetwork<br>使⽤<br>安装位置<br>/root/stable-diffusion-webui/models/hypernetworks
Hypernetwork<br>特点<br>模型⽂件适中,~87MB<br>适合学习较⼤的概念,如艺术⻛格、某些⼩众物品<br>在较低训练步数就能看到⼀些结果,训练较容易
Dreambooth及LoRA
DreamBooth<br>只需上传 3-5 张指定物体的照⽚, <br>再⽤⽂字描述想要⽣成的背景、动作或表情, <br>就能让指定物体“闪现”到你想要的场景中,动作表情也<br>都栩栩如⽣。
在推理时,我们可以将唯⼀标识符植⼊不同的句⼦中,以在不同的上下⽂中合成主题。
(a) 微调低分辨率⽂本到图像模型,输⼊图像与包含独特信息的⽂本提示配对标识符和主体所属类别的名称。<br>(b) 使⽤从我们的输⼊图像集中获取的成对的低分辨率和⾼分辨率图像微调超分辨率组件,这使我们能够保持对主体⼩细节的⾼保真度。
如何训练<br>基础模型<br>DreamBooth 微调对超参数⾮常敏感,容易过拟合。
https://colab.research.google.com/github/ShivamShrirao/diffusers/blob/main/examples/dreambooth/<br>DreamBooth_Stable_Diffusion.ipynb#scrollTo=y4lqqWT_uxD2
DreamBooth<br>DreamBooth 容易过拟合。为了获得⾼质量的图像,<br>我们必须在训练步骤数和学习率之间找到⼀个“最佳点”。<br>DreamBooth 需要更多的⼈脸训练步骤 800-1200 步运<br>⾏良好。<br>除了 UNet 之外,训练⽂本编码器对质量也有很⼤影响。<br> (train_text_encoder)
DreamBooth<br>DreamBooth 容易过拟合。为了获得⾼质量的图像,<br>我们必须在训练步骤数和学习率之间找到⼀个“最佳点”。<br>DreamBooth 需要更多的⼈脸训练步骤 800-1200 步运<br>⾏良好。<br>除了 UNet 之外,训练⽂本编码器对质量也有很⼤影响。<br> (train_text_encoder)
训练⼈脸时使⽤ Prior Preservation<br>如果我们尝试将⼀个新⼈合并到模型中, <br>我们想要保留的类可能是 person<br>结合使⽤新⼈的照⽚和其他⼈的照⽚来减少过度拟合
模型⽂件很⼤,2-4GB <br>适于训练⼈脸、宠物和物件 <br>使⽤时需要加载模型 <br>可以进⾏模型融合,跟其他模型⽂件融合成新的模型 <br>本地训练时需要⾼显存,>=12GB <br>推荐训练⼈物*画⻛
LoRA
https://github.com/bmaltais/kohya_ss
https://jihulab.com/hunter0725/sd-webui-additional-networks
子主题
https://jihulab.com/hunter0725/sd-webui-additional-networks
https://jihulab.com/hunter0725/sd-webui-additional-networks
模型⼤⼩适中,8~140MB <br>使⽤时只需要加载对应的 LoRA 模型,可以多个不同的(LoRA 模型 + 权重)叠加使⽤ <br>可以进⾏ LoRA 模型其他模型的融合 <br>本地训练时需要显存适中,>=7GB <br>推荐训练⼈物
模型资料
链接:https://pan.baidu.com/s/1tQ4uIcs4zZHCTGjnc6vO-A?pwd=GEEK提取码:GEEK