Stable Diffusion 3架构图
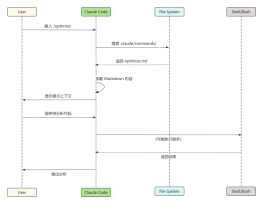
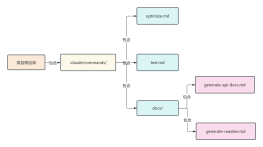
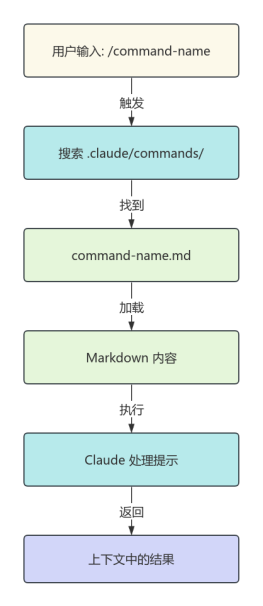
2026-01-31 21:46:19 0 举报Stable Diffusion 3 (SD3) MMDiT 架构图:文生图新范式深度解析 Stable Diffusion 3 彻底革新了生成式 AI 范式。本 ProcessOn 模板为你揭秘其核心 MMDiT (多模态扩散 Transformer) 架构。 核心亮点: 1.颠覆性 MMDiT: 详细呈现其取代 U-Net 的 Transformer 结构,理解多模态信息如何深度融合。 2.双流交互机制: 精准描绘文本流与图像流的并行处理与关键的交叉注意力机制,透彻理解提示词如何精细控制图像生成。 3.结构清晰简洁: 即使 ProcessOn 样式受限,依然通过分段式布局与严谨逻辑流,确保图表的学术准确性与视觉易读性。
模板推荐
作者其他创作
大纲/内容






0 条评论
下一页