CFG scale
text prompt
CLIP model
768-value vector
tokenizer
Decoder
latent noisy image
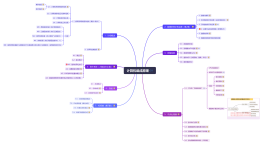
名词说明:1、CLIP model:是deep learning模型,Open AI开发,用于计算机文字转图片(Contrastive Language-Image Pre-Training model)将text prompt转化成tokenizer,将taken转化成向量,然后生成noise。2、Embedding:是基于CLIP模型训练的模型生成的一个向量3、Latent diffusion model:生成速度快、对计算资源和内存消耗需求小的扩散模型。依据seed的数值随机生成tensor,4、VAE:是neural network,把图片转码成Latent或者将latent解码成图片核心能力是精调图片5、U-Net model:预测并生成noise数据。把embedding向量通过Text transformer(的程序运行机制)转化成noise分布预测值。(1)Noise is sequentially added at each step.(2)Noise predictor estimates the total noise added up to each step.6、Fine-tuned models:是针对某个风格的图片而训练的模型7、Text Conditioning:通过转化prompt生成noise数据,从而指导生成图片样式8、设置参数:(1)sampler:The diffusion sampling method ,Default is “K_lms”sample特性取决于小模型的训练方式和数据集(2)seed: The seed used to generate your imagenoise数据,强关联图片效果(3)steps:How many steps to spend generating(diffusing) your image重复的演算,呈现结果(4)CFG scale: CFG scale adjusets how much the image will be like your prompt(5)Prompt:提示词
Scheduleralgorithm\"reconstruct\"
Encoder
Latent space
Prompt
Text conditionedlatent U-Net
VAE transforms the image to and from the latent space
picture
4*64*64tensor
Seed
U-Net model1、Noise is sequentially added at each step。2、Noise predictor estimates the total noise added up to each step。
VAriational Autoencoder(VAE)
Predicted noise
steps
New latent image
token
Gaussian noise N(0,1)
Frozen CLIPText Encoder
1、Random tensorin latent space2、Controlled by seed
repeat NN:sampling steps
Embedding