Llama 3.1 vs DeepSeek-R1 架构全景对比
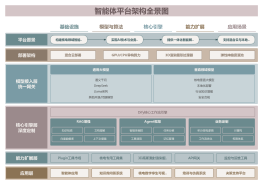
2026-02-01 16:33:56 0 举报本图表从底层架构(MLA vs GQA)、训练逻辑(GRPO强化学习 vs 迭代RLHF)及推理机制三大维度,全景拆解了全球最火的两大模型。不仅清晰展示了DeepSeek如何凭“极低成本”逆袭的秘诀,更复现了Llama作为开源基石的稳健布局。 无论你是AI从业者、论文党,还是想要捕捉大模型风口的创作者,这张全景图都是你梳理技术脉络、寻找下一个技术爆发点的必备利器!点击获取,带你一图看懂大模型架构的进化逻辑。
模板推荐
作者其他创作
大纲/内容





0 条评论
下一页