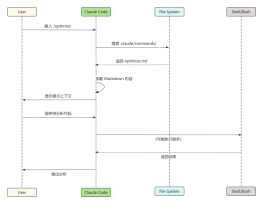
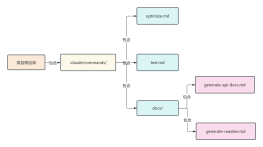
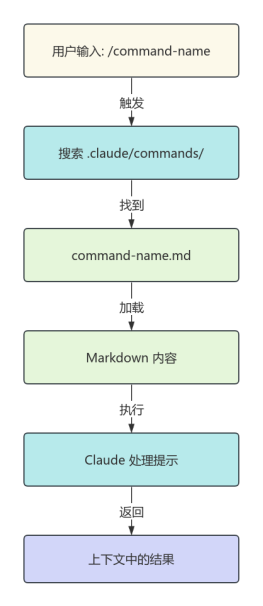
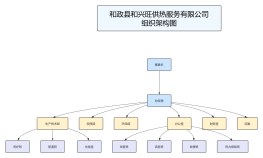
Shared
…
t4
concatenate
t5
t3
Cross-Entropy Loss FP32
t8
3
DeepSeekMoE
RMSNorm FP32
Multi-Head Latent Attention(MLA)
NrFP8 Mixed Precision
… …
RMSNorm FP32
Output Hidden
t1
t2
2
Input Hidden ut
Dispatch: All-to-All FP8
Transformer Block × L
{span class=\"equation-text\" contenteditable=\"false\" data-index=\"0\" data-equation=\
1
Main Model(Next Token Prediction)
concatenation
Output Head BF16
FP8
Transformer Block × L
29
Embedding Layer BF16
Shared Expert
Latent
RMSNorm FP32
t7
Attention FP8 Mixed Precison
Top-Kr
{[span class=\"equation-text\" contenteditable=\"false\" data-index=\"0\" data-equation=\
t6
Multi-Head Attention BF16
Router FP32
Transformer Block FP8 Mixed Precison
apply RoPE
Cross-Entropy Loss FP32
Feed-ForwardNetworkFP8 Mixed Precison
Nr-1
Target Tokens
Embedding Layer BF16
Linear Projection BF16
NsFP8 Mixed Precision
Output Hidden ut
Transformer Block FP8 Mixed Precison
Output Head BF16
Linear Projection BF16
Input Tokens
MTP Model 2(Next3 Token Prediction)
MTP Model 3(Next4 Token Prediction)
MTP Model 1(Next2 Token Prediction)
Routed Expert
Combine: All-to-All BF16/LogFMT
FP32
Input Hidden ht
Latent
Cached During Inference