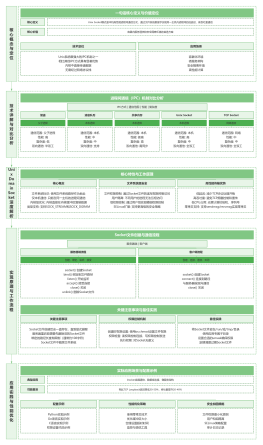
缓冲池 Buffer Pool<br>
Buffer Pool的控制块<br>
Buffer Pool 的预读特性<br>
InnoDB怎么在不查询磁盘的情况下知道 id = 6的记录也位于 1001号页呢?
Innodb的预读不仅只读取本次所需的一个页面,还可能读取和该页面相邻近的其他页面
Buffer Pool的管理<br>
Buffer Pool的初始化<br>
申请空间<br>
划分空间<br>
3种页
1、free page<br>
2、clean page<br>
3、dirty page<br>
针对这3种页,InnoDB使用3种链表维护<br>
free list<br>
意义<br>
误区说明<br>
flush list<br>
lru list<br>
链表中的节点不是缓存页本身,而是页对应的控制块<br>
Buffer Pool缓存淘汰
使用LRU会遇到的问题<br>
预读<br>
大量数据涌入<br>
解决方法<br>
冷热分离LRU
优化点1:midpoint<br>
优化点2:old_blocks_time<br>
优化点3:减少热页在链表移动<br>
缓冲页的哈希处理<br>
脏页刷盘<br>
1、从LRU 链表的冷数据区刷新部分页面到磁盘<br>
2、从 flush 链表中刷新一部分页面到磁盘<br>
3、主动刷盘内存池中被淘汰的脏页<br>
多个Buffer Pool<br>
Buffer Pool分块<br>
目的<br>
块大小<br>
Buffer Pool 预热<br>
Buffer Pool配置参数<br>
innodb_page_size<br>
innodb_old_blocks_pct<br>
innodb_old_blocks_time<br>
innodb_buffer_pool_instances<br>
innodb_buffer_pool_dump_at_shutdown<br>
innodb_buffer_pool_dump_pct<br>
innodb_buffer_pool_load_at_startup<br>
日志缓冲区 Log Buffer<br>
刷盘<br>
3种策略<br>
<font color="#000000">1、</font>每隔1秒从 log buffer 写入OS cache,并马上刷盘,<font color="#000000">mysql服务故障或者主机宕机则丢失1秒数据。</font><br>
2、<font color="#f44336">事务提交时</font>,立刻从 log buffer 写入 os cache, 并马上刷盘,mysql服务故障或者主机宕机不会丢失数据,但会频繁发生磁盘IO。<br>
3、<font color="#f44336">事务提交时,立刻从 log buffer 写入 os cache,每隔1秒刷盘</font>,mysql服务故障不会丢失数据,因为数据已经进入操作系统缓存,与mysql进程无关了,主机宕机则丢失1秒数据。
除此之外,当redo/undo日志缓冲区满了之后,也会触发刷盘。