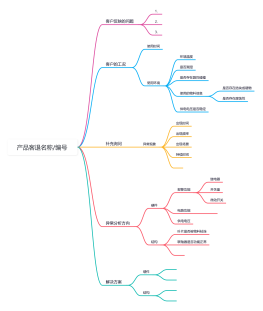
解决方案(读多写少)
1.对于并发几率很小的数据,很少会发生缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
2.就算并发很高,业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
3.如果不能容忍缓存数据不一致,可以通过加分布式读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁。
4.也可以用阿里开源的canal通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂程度。
解决方案(读少写多)
1.直接操作数据库
2.把缓存作为数据读写的主存储,异步将数据同步到数据库