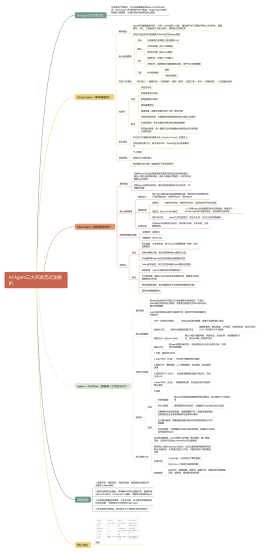
AI Agent产品经理面试知识提纲
2025-07-25 11:35:41 0 举报AI智能生成
在为AI Agent产品经理职位的面试进行准备时,需紧密围绕产品知识、市场洞察、技术理解、战略规划、用户研究、业务流程、数据驱动和团队协作等方面。阐述期望候选人能够结合AI领域的前沿技术,展示强大的产品思维、创新能力和市场适应性。 文件类型描述:结合职位要求,面试候选人应当携带一份详细的个人简历,附有相关工作经历和项目案例的附件,以及对未来AI产品方向的精辟见解报告。 修饰语描述:候选人需具备深刻的专业知识、清晰的表达能力、敏锐的市场洞察力和强大的解决问题的能力。同时,应展现积极主动、创新思维、逻辑清晰及优秀的领导力和团队协作精神。
模板推荐
作者其他创作
大纲/内容


Collect

Collect

Collect
Collect
0 条评论
下一页

