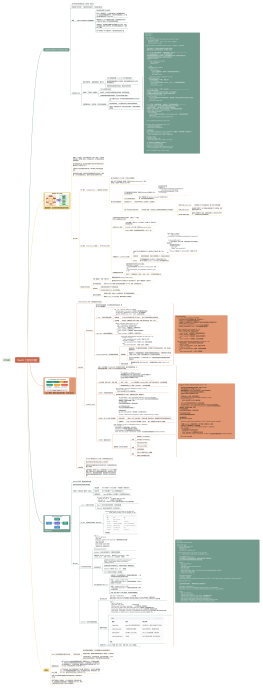
RAG 和 Deep Research Agent 差在哪里
区别
RAG 就像让你的助手去查字典
问一个问题,他翻到对应词条,念给你听,完事
只能解决词“词条型“问题
单跳问答
"等待期是多少天"
1 轮问题RAG完全够用
两跳推理
"A 公司的 CEO 毕业于哪所大学"
2-3 轮RAG勉强应付
研究型问题,后面的搜索依赖前面的结果,需要动态决策,RAG 的一次检索根本做不到
研究型问题
"五大车企固态电池路线对比"
10-20 轮 RAG无法处理
复杂分析
"某政策对三个行业的差异化影响"
20+ 轮RAG无法处理
Deep Research Agent(深度研究 Agent)要做的事
①动态决定下一步搜什么
②把多轮检索的信息整合在一起
③知道什么时候信息够用了、可以停下来
支撑 Deep Research Agent 的四根柱子
训练数据
模型没办法凭空学会做复杂研究,它需要看大量"有人做过这件事"的轨迹样本
从问题出发,一步一步搜索、判断、调整,直到拿到答案的完整过程
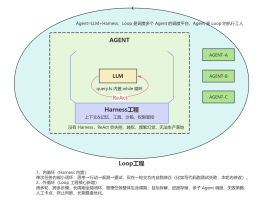
Agent 框架
模型的"行动逻辑"——它按什么格式输出思考,按什么方式调用工具,工具结果回来之后怎么继续推理
最基础的框架叫 ReAct(推理与行动,Reasoning and Acting)
训练系统
有了数据和框架定义,还需要通过 SFT(监督微调,Supervised Fine-Tuning)让模型学会基本格式
再通过 RL(强化学习,Reinforcement Learning)让它学会在不同情况下做出更好的策略选择
工具集
Agent 靠工具和外部世界交互,工具设计的好坏直接影响 Agent 的能力边界
核心四件套
Search(搜索引擎)
Visit(网页内容提取)
Scholar(学术文献检索)
Python(代码执行)
四者得关系
训练数据决定了模型能学什么
Agent 框架决定了这些能力怎么被激活和组织
训练系统把数据转化为模型参数里的能力
工具集则是 Agent 和世界产生联系的接口
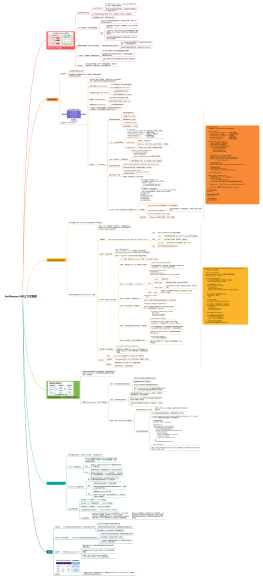
ReAct:把"想"和"做"交织在一起
核心思想
① Thought(思考)
模型看着当前所有信息,先想一想:我现在知道什么,还缺什么,下一步应该干什么
② Action(行动)
根据思考结果,调用一个工具——搜索一个关键词,或者打开一个网址
③ Observation(观察)
工具执行完,把结果读进来,追加到对话历史,然后回到第①步
工具调用的错误处理是第一优先级要做好的事
一旦失败、整个 Agent 崩掉的代价远比多写几行 try/except 要高
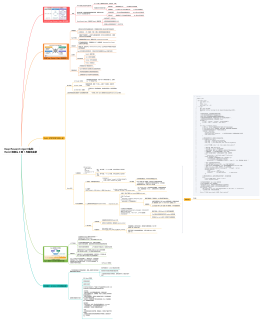
Demo 演示
1. 函数概览
def react_loop(
user_query: str,
llm,
tools: dict,
max_steps: int = 10
) -> str:
输入:用户问题、一个 LLM 对象、可用工具字典、最大执行步数。
输入:用户问题、一个 LLM 对象、可用工具字典、最大执行步数。
2. 核心逻辑拆解
A. 初始化:保留完整对话历史
messages = [<br> {"role": "system", "content": SYSTEM_PROMPT},<br> {"role": "user", "content": user_query}<br>]
设计意图
必须保留完整历史,而不是只保留最近几轮
ReAct 的核心是 “推理链”。如果丢弃了早期的搜索结果(Observation),模型会忘记 “我已经知道什么”,从而导致重复搜索相同内容,浪费 Token 和步数
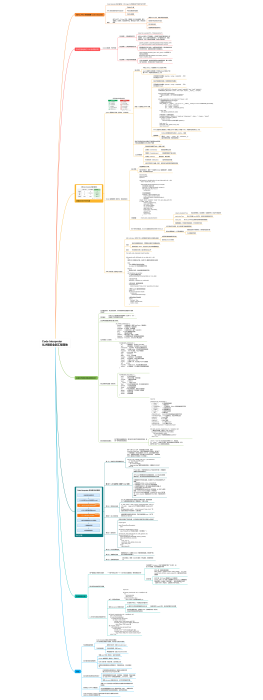
B. 主循环:<br>思考 (Thought) -> 行动 (Action) -> 观察 (Observation)<br>
for step in range(max_steps):<br> response = llm.chat(..., tool_choice="auto")
tool_choice="auto":它把决定权交给模型:“如果你觉得信息够了,就直接回答(Finish);如果觉得不够,就调用工具(Act)
C. 工具调用与异常处理 (Production-Grade)
response.tool_calls
1.解析:取出工具名 (tool_name) 和参数 (tool_args)。<br>
2.执行 (Try/Except):<br>try:<br> observation = tools[tool_name](**tool_args)<br>except Exception as e:<br> observation = f"工具调用失败..."
搜索引擎超时、网络波动、API 限流每天都在发生。
优雅降级
如果不捕获异常,整个 Agent 会直接崩溃。这里的做法是把 “错误信息” 当作一个 “Observation” 反馈给 LLM
让它决定是 “换个工具” 还是 “换个搜索词”,而不是直接死掉
3.记录历史 (严格的顺序):<br>messages.append(response.to_message()) # Assistant 的消息 (Thought+Action)<br>messages.append({... "role": "tool" ...}) # Tool 的结果 (Observation)
顺序不能乱,这是 OpenAI API 格式的强制要求
Tool 消息必须紧跟在触发它的 Assistant 消息后面
并且通过 tool_call_id 配对。顺序错了会直接报错
D. 终止条件
1.正常结束
如果模型没有调用工具 (else 分支)
说明它认为信息足够,直接返回 response.content
2.步数耗尽<br>
last_content = next(...)
return f"[已达 {max_steps} 步上限] {last_content}"
不直接报错,用户等了很久,哪怕是不完整的答案,也比 “程序崩溃” 或 “无结果” 要好。
<br>
返回了最后一条有效的模型输出,让用户知道 Agent 大概卡在哪一步。
Agent 能跑了后的很快遇到的问题
上下文膨胀
长任务里 messages 随轮次线性增长——<br>假设每步平均产生2500 token,<br>跑10步就是25000 token,跑15步就是37500 token
在大部分模型的"舒适区"之外,注意力开始稀释,<br>靠后的内容权重更高,靠前找到的关键信息越来越容易被忽视
注意力机制的物理特性
上下文超过某个阈值之后,结果反而会变差
策略停滞
模型每次生成 Thought 的时候,要从几万 token 的历史里推理出"我还缺什么信息",这个推理本身很容易出错
模型用几乎一样的关键词反复搜索,或者在同一个子问题上绕圈,因为它"看不见"前面几步已经找到答案了。
引入一个固定大小的"研究摘要"——每轮执行完,不是把原始结果堆进上下文,而是更新一份结构化的摘要,记录"目前已知的信息"和"还没解决的子问题",上下文大小保持常量,无论跑多少轮都不会溢出。
IterResearch 的框架
系统提示:让 ReAct 工作的隐藏关键
一个好的系统提示不是写越多越好,是每一条都针对你在测试里看到的真实问题写的
应该先跑起来,让 Agent 真实地出问题
然后有针对性地往系统提示里加约束
一开始就把系统提示写得很长,通常效果不好,模型会"读不进去"
系统提示需要做三件事
定义 Agent 的角色
规定输出格式
设置行为边界
SYSTEM_PROMPT = """你是一个专业的研究型 AI 助手,擅长通过多轮工具调用完成复杂信息检索任务。
工作方式:
- 遇到问题,先分析需要找哪些信息,再逐步检索
- 每次工具调用之前,先想清楚:调这个工具是为了解决哪个具体的信息缺口
- 拿到工具结果后,判断这个信息够不够用;不够用就继续搜,够用了就综合作答
- 如果同一个搜索词搜了两次没有新信息,换一个角度重新搜,不要重复无效操作
输出格式:
- 调工具之前,先用一两句话说明你要做什么(Thought)
- 工具结果回来后,先评估结果质量再决定下一步
- 最终回答时,注明每个关键信息的来源
边界:
- 如果信息来源之间有矛盾,明确指出,不要自己"融合"矛盾的信息
- 如果某个问题在现有检索结果里找不到答案,直接说找不到,不要编造
"""