
Java 要点
2019-09-03 13:03:44 1 举报AI智能生成
JDK和JVM重点合计,学习复习 Java 大纲,面试要点等一一包含。
java
面试
JVM
模板推荐
作者其他创作
大纲/内容
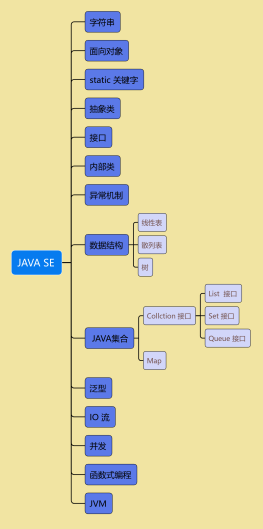
Java 基础
基础类型
集合
List 无序列表集合
Vector
线程安全
性能偏低
数组实现
ArrayList
非线程安全
数组实现,两倍扩容
LinkedList
链表实现,近乎无界
非线程安全,
Map 键值对
HashMap
装载因子
并发死锁
jdk7/8 实现差别
数组链表红黑树
LinkedHashMap
Hashtable
TreeMap/红黑树
Set 不包含重复对象
TreeSet
HashSet
LinkedHashSet
通过对应的 Map 结构取键实现
Queue
PriorityQueue
juc.BlockingQueue
Deque
ArrayDeque
LinkedList
fail-fast/fail-safe
通过修改次数modCount来比对,在迭代时比较,不一致快速失败
比如迭代中移除,直接通过集合移除会异常,需要通过迭代器移除
ju包下通常是 failfast,juc 下多为 fail safe
工具类
Arrays
排序,二分查找
数组(范围)比较,equals 对比
范围复制,装填,hashCode
交集,切分
Collections
不可变集合
安全类型对象(类型不匹配抛出异常)
空集合
同步集合<br>
常用最大最小排序等方法
<b>泛型</b>
编译时安全类型检查
提高了安全性
检查时机从运行时提前到编译时
避免类型强转,提高性能
参数化类型,提高代码复用
只能使用引用类型,不能使用基元类型
在没有具体类型限定的情况下使用都是 Object 类型
只在编译期有效,编译后被擦除,兼容老版本
泛型通配
? 适配 Object/任意类型
?extends E 适配 E 及其子类
? super E 适配 E 及其父类
& 组合多个类型约束
泛型约束,一切归结于类型擦除
不能使用基元类型实例化泛型类型(引用类型包含实际的类型信息,方便检查)<br><strike>List<int> list = new ArrayList<>();</strike>
不能实例化泛型参数(实例化需要申请内存,泛型不能确定所有字段,所以不能确定内存大小)<br><strike>T t = new T();</strike>
不能实例化泛型数组(类型不确定导致单元大小不确定导致申请内存不确定)<br><strike>T[] t = new T[1];</strike>
不能 instanceof Generic<E>(运行时类型擦除,不会保留泛型信息)<br><strike>if (c instanceof T) {...}<br>if (c instanceof List<T>) {...}</strike><br>
不能泛型类型强转 (List<Long>) list = new ArrayList<Integer>()<br>
不能定义泛型类型的静态变量(静态类型需要在类上分配内存,不能确定需要分配的内存大小)
不能重载在类型擦出后类型相同的方法<br><strike>public void print(Set<String> strSet) { }<br>public void print(Set<Integer> intSet) { }</strike>
不能直接或间接扩展 Throwable<br><strike>class MathException<T> extends Exception { /* ... */ }</strike><br>
泛型类型获取
只能通过继承泛型类、传入具体Class 信息的情况下通过反射获取 T.class<br>Class <T> entityClass = (Class <T>) ((ParameterizedType) getClass().getGenericSuperclass()).getActualTypeArguments()[0]; <br>
反射
定义和目的
定义:<font color="#c41230"><b>运行时 </b></font>获取类的所有属性和方法,调用实例的任何字段和方法;<br>
目的:<b><font color="#c41230">运行时 </font></b>获取类的信息,动态的创建对象和编译;实现解耦<br>
原理
java 类对象都将编译成 class 字节码文件,通过读取类字节码文件来获取类的属性和方法等信息
特点
优点:运行期间动态执行方法,灵活,解耦<br>
缺点:性能受影响,总是低于直接执行 java 代码
用途
JDBC中,利用反射动态加载了数据库驱动程序。
调用 Class.forName("驱动类")时,调用了内部静态方法,注册到 DriverManager 中<br>
Web服务器中利用反射调用了Sevlet的服务方法。
IDE 开发工具利用反射动态刨析对象的类型与结构,动态提示对象的属性和方法。
动态代理,如 RPC,spring<br>
Class.forName 过程解析
1. Class.forName 通过类名找到字节码
2. 将字节码装载进方法区/元空间
3. 构造 Class 实例,类型信息指向方法区中对应类信息
代理
静态代理
interface IBiz {void execute();}<br>class BizImpl { void execute() {...}}<br>class ProxyBizImpl {<br> BizImpl biz;<br> void execute() {<br> print("before");<br> biz.execute();<br> print("after");<br> }<br>}
<b>优点:</b>性能无差别,在不改变现有代码的情况下扩展已有代码<br><b>缺点:</b>代理类繁多? 接口扩展时所有代理都要变更<br>
动态代理
优缺点
优点:<br>1. 可以运行时动态生成代理对象<br>2. 在被代理对象变更时,没有特殊代理变动不需要修改代理类
缺点:<br>1. 性能有影响<br>2. 元空间占用<br>3. JDK 代理时需要抽象出业务接口,然后代理该接口<br>
JDK 代理
基于接口和反射实现,<b>必须实现要代理的接口才能代理</b>
<b>Proxy</b>.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,<b>InvocationHandler</b> h)
private Object target;<br><br>ClassLoader cl = target.getClass().getClassLoader();<br>Class<?>[] il = target.getClass().getInterfaces();<br><br>return Proxy.newProxyInstance(cl, il, new InvocationHandler() {<br> public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {<br> System.out.println("前拦截...");<br> Object result = method.invoke(target, args); // <font color="#c41230" style="">不能调用 proxy,否则永远调用不到实际代码</font><br> System.out.println("后拦截...");<br> return result;<br> }<br>});<br>
CGLIB 代理
可以在没有接口的情况下实现动态代理,也可以代理接口
原理:通过 ASM 继承扩展被代理类,通过方法索引调用被代理对象的方法,通过父类和增强实现,实现类似静态代理
Enhancer enhancer = new Enhancer();<br>enhancer.setSuperclass(Waiter.class);<br>enhancer.setCallback(new WaiterProxy());<br>Waiter w = (Waiter) enhancer.create();<br>w.order("1111");<br><br>class WaiterProxy implements MethodInterceptor {<br> // 增强对象,代理方法,代理方法参数,方法代理<br> public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {<br> System.out.println("您好!");<br> Object result = proxy.invokeSuper(obj, args);<br> System.out.println("很高兴为您服务。");<br> return result;<br> }<br>}
使用场景
Spring AOP
Hibernate
RPC 调用实现
并发多线程
并发数据结构
ConcurrentHashMap
ConcurrentSkipListMap
CopyOnWriteArrayList
ConcurrentSkipListSet
线程和进程
线程
CPU 调度的基本单元
进程之前有一个线程
没有独立的内存空间,共享所在进程的内存,文件I/O
线程间通讯简单
进程
资源分配的最小单元
独立的内存空间
进程间通讯复杂
版本变化
jdk8
Lambda表达式详解
Optional、Stream详解
函数式接口、方法引用详解
重复注解、扩展注解、并行数组详解
CompletableFuture详解
jdk9-11
JAVA模块化详解
JDK自带HTTP Client工具详解
Switch新语法、JAVA脚本详解
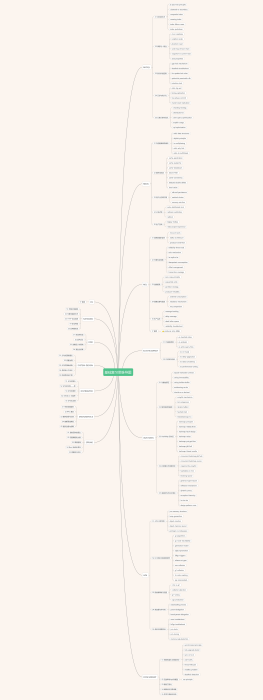
JVM原理和优化
运行时内存区域
堆(公有)
特点
唯一存放对象实例的地方(<font color="#c41230">随着优化技术发展,不再绝对</font>)
垃圾回收工作的主要区域
不要求物理连续,但逻辑上连续
所有线程共享区域
不同维度不同划分
垃圾分代收集划分
新生代 (1/3)
Eden (8/10)
From Surviver (1/10)
To Survivor (1/10)
老年代 (2/3)
线程分配
多个线程分配缓冲区 TLAB (Thread Local Allocate Buffer) - <i>局部性原理 -空间</i><br>
虚拟机栈(线程私有)
为 java 方法调用服务,存有集本数据类型和堆对象的引用
栈帧,运行时基础数据
操作数栈
局部变量表
所有都是值引用,对象传递的是引用地址
引用对象在方法调用中被重新赋值,在栈帧出栈后原栈帧数据全部清空,所以不影响调用前的赋值
引用对象在方法内的的调用导致变化会反馈给外部对象
所需内存在编译期就确定了
局部变量表的第 0 位指向当前实例 this
返回地址
正常退出,返回上级方法地址
异常退出,由异常表来确定,栈帧中一般不保存这部分信息<br>
动态链接
动态编译后的调用地址,和即时编译优化有关
本地方法栈(线程私有)
为虚拟机本地方法服务
程序计数器(线程私有)
行号指示器,每个线程持有一个<br>
方法区/元空间(公有)
特点
各个线程共享的内存区域
存储被虚拟机加载的类信息,常量,静态变量,即时编译器编译的代码<br>
包含运行时常量池
JDK 8 变化
元空间详解
内存回收、分配
GC 搜索算法
引用计数算法
不能解决循环引用问题
根搜索算法
从 GC Root 开始搜索,当一个对象不与任何引用链相连,表明对象不可达、不可用<br>
GC Root(实例对象)
栈内引用对象
本地方法栈内的引用对象(JNI)
方法区内的常量引用对象
方法区内的静态引用对象
GC 回收算法
标记清除算法
标记所有需要回收的对象,然后统一回收
缺点:<br>1. 标记和收集效率都不高<br>2. 内存碎片
标记整理算法
在标记清楚的过程后,将内存统一向一端移动,收集边界外的内存
复制算法
内存空间对分,每次使用一部分,GC后存活对象复制到另一部分
缺点:<br>1. 内存浪费太大<br>2. 存活对象较大时导致大量复制
分代收集算法
根据对象存活周期不同将内存划分为多个块,每个块可以根据各自对象的特点适用不同的回收算法<br>
新生代 1/3<br>
Eden 8/10
From survivor 1/10
To survivor 1/10
老年代 2/3
Minor GC 新生代
由 Eden 区满触发
Major GC老年代/Full GC 所有区域
发生时通常有一次 Minor GC,不绝对,速度比 Minor GC 慢10 倍以上<br>
出现时机
1. 老年代空间不足
2. 方法区空间不足
3. 显式调用 System.gc() 触发
4. 通过Minor GC后进入老年代的大小大于老年代的可用内存
收集器分类
串行收集
不需要多线程处理,高效,但是浪费多核且只适合小数据量的情况(100M)
并行收集
并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。<br>而且理论上CPU数目越多,越能体现出并行收集器的优势。后台处理和科学计算
并发收集
相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,需要暂停整个运行环境,而只有垃圾回收程序在运行。<br>因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长。Web服务器
收集器
新生代
Serial
单线程,标记整理
ParNew
Serial 多线程版本
Parallel Scavenge
复制算法,多线程,可控制吞吐量<br>
老年代
Serial Old
单线程,标记整理
Parallel Old
Parallel Scavenge 老年代版本,多线程,标记整理<br>
CMS<br>Concurrent Mark & Sweep清除
最短回收停顿为目的的收集器,并发收集、低停顿
回收的步骤
1. 初始标记,仅标记 GC Roots 直接关联的对象,速度很快
2. 并发标记,GC Roots 跟踪<br>
3. 重新标记,修正并发标记期间用户活动引起变动的对象的标记记录。比初始标记时间长,远比并发标记时间短
4. 并发清除
5. 清除重置
缺点
CMS 对 CPU 资源非常敏感
不能处理浮动垃圾
标记清除算法会导致内存碎片,通过配置可以实现 FullGC 后整理内存,但是会导致停顿边长
混合支持
G1
标记整理,精准控制停顿
1. 将内存区域划分为多个大小固定的区域,并跟踪区域内垃圾堆积的程度。<br>2. 在后台维护一个优先列表,每次根据允许的收集时间,优先回收垃圾最多的区域<br>
步骤
1. 开始标记
2. 并发标记
3. 再次标记
4. 并发清理
对象的回收与自救
真正回收一个对象最少需要两次标记过程
1. 对象不可达时标记第一次
2. 没有重写 finalize 方法,或已经执行过 finalize 方法,将被回收
3. 如果重写了 finalize 方法且没有执行过时(finalize 有且最多执行一次),<br>放入一个 F-Queue 队列,由虚拟机创建低优先级线程 Finalizer 来执行队列中对象的 finalize 方法,<br>不承诺等待结束。(耗时或者死循环等将会导致回收系统的崩溃)<br>
4. 对 F-Queue 中对象进行二次标记,如果没有回到引用链上,将被回收<br>
不推荐使用 finalize 方法,finalize 能做的 try/finally 都能做
方法区回收(元空间不一样,详见文档)
废弃常量
无用的类
不存在该类的任何实例
加载该类的 ClassLoader 被回收
该类的 Class 对象没有任何引用,不能通过反射访问到该类
内存分配策略
优先 Eden 分配,不够发生 Minor GC
大对象(需要大量连续的内存空间的对象)直接进入老年代,避免 Eden/Survivor 之间大量复制<br>
长期存活进入老年代,默认年龄超过 15 进入
当某个年龄的内存总和大于 Survivor 空间的一半,大于或等于该年龄进入老年代<br>
空间分配担保
类、加载、调用
字节码
平台无关性的基石
文件结构
符号引用和直接引用
符号引用
一组符号描述所引用的目标
符号可以是任何字面量,只要可以没有歧义的定位到目标即可<br>
符号引用与虚拟机内存布局无关,引用的目标不一定已经加载到内存了<br>
直接引用
可以直接指向目标的指针、偏移、句柄<br>
与虚拟机内存布局有关,同一符号引用在不同 jvm 实例中翻译出来的直接引用一般都不会相同<br>
有了直接引用,引用的目标一定存在于内存中了<br>
类生命周期
加载(类加载机制)
1. Loading 加载
类加载器获取类的二进制流,文件,网络等等
2. Linking 连接
2.1 Verification 验证<br>
文件格式校验
验证四个阶段
文件格式验证(字节流验证)
验证文件格式,如魔数/版本/常量/方法等等
确保正确解析并存储与方法区中
<font color="#c41230">验证通过后保存到方法区,后面的三个阶段都是基于方法区内数据结构进行的</font>
元数据验证
字节码描述的信息进行语义分析,确保符合 Java 规范。如:<br>* 是否有父类<br>* 父类是否有 final 修饰<br>* 非抽象类是否实现了抽象父类的抽象方法 等等
字节码验证
主要分析方法体,数据流和控制流的分析,确保不会维护虚拟机的安全。如:<br>* 数据类型和指令是否匹配,int 操作符不会操作 long 数据<br>* 跳转指令不会跳转到方法外,等等
符号引用验证
发生在符号引用转为直接引用的时候,确保解析正常通过<br>
对类自身外(常量池中的各种符号引用)的信息进行匹配性的验证。如:<br>* 能否通过全限定类名找到对应的类<br>* 能否找到对应方法和字段<br>* 符号引用中的是否满足访问限定,private,protected 等
2.2 Preparation 准备<br>
正式为类变量分配内存并设置类变量初始值的阶段,在方法区中进行<br>
仅分配 static 修饰的变量,不包括实例变量,实例变量实例时分配
static 变量分配的值为类型的初始值,不是类中实际定义的值,如:<br>static int i = 10,在准备阶段 i = 0;<br>赋值的 putstatic 指令位于初始化调用的 clinit 中
初始化类型的方法表(动态分派重要应用 - 重写 性能优化数据结构,查看那执行引擎部分)
2.3 Resolution 解析
虚拟机将常量池内的符号引用替换成直接引用的过程<br>
解析内容<br>
类和接口解析
字段解析
方法解析
接口方法解析
3. Initialization 初始化
触发初始化的场景
类初始化
1. new/getstatic/putstatic/invokestatic 的时候,没有初始化需要初始化<br>
2. 反射调用类的时候
3. 调用类时,其父类没有初始化的情况
4. 虚拟机启动时执行的主类 main(String[] args)<br>
接口初始化
同样会按需生成 clinit (静态变量的初始化在这里完成)<br>
子类接口初始化不需要先执行父类接口的 clinit
真正用到父类接口定义的变量时才会初始化
结构的实现类在初始化的时候一样不会调用父类接口的 clinit 方法
完成主观定义的类变量和静态代码块(执行类的 clinit 方法)<br>
clinit 是通过编译器收集类变量和 static 块合并产生的<br>
clinit 收集代码的顺序和源文件定义顺序一致
静态语句块只能访问之前定义的静态变量,能给之后定义的静态变量赋值但不能访问
虚拟机保证了执行子类 clinit 之前,父类的 clinit 执行完毕
按需生成 clinit
虚拟机保证线程安全的执行 clinit 方法(加锁同步)
使用
卸载,方法区/元空间 GC<br>
类加载器
类加载器和类本身唯一确定类在虚拟机中的唯一性
类加载器类型<br>
启动类加载器,c++ 实现,虚拟机的一部分
BootstrapClassLoader:加载 JAVA_HOME/lib 下的内容,不能直接被 Java 程序引用<br>
其他所有类型类加载器,java 实现,<br>继承自抽象类 ClassLoader
ExtensionClassLoader:扩展加载器,负责加载 /lib/ext 下的包
ApplicationClassLoader:应用加载器,加载用户路径下的包
双亲委派模型
要求出了顶级启动类加载器外,其余的类加载器都有自己的父类加载器,通过组合复用父类加载器。<br>步骤:<br>1. 收到一个加载类的请求,首先委派给父类加载器去加载<br>2. 每个类加载器都是如此,最后将会由顶级启动类加载器执行加载<br>3. 如果父类加载器不能加载成功,子类才尝试自己去加载
类加载器具有一定优先级,保证基础类的统一性,维护了程序的稳定性<br>
破坏双亲委派模型
JNDI/JDBC/OSGi 等
Thread.setContextClassLoader
对象及模型
对象引用
实现方式
句柄访问
句柄池
句柄包含对象实例数据和类型信息的地址信息<br>
GC对象移动时,只需要修改句柄,不需要调整修改 reference<br>
直接指针
reference 直接指向实例数据所在地址
对象移动时需要修改 reference 指向的地址
访问速度快, Hotspot 采用的方式是直接指针
对象引用分类
强引用
等号引用
只要强引用存在,JVM 就不会回收该对象
软引用
SoftReference,关联有用,但是非必需对象
导致内存溢出时,列入回收范围二次回收<br>
弱引用
WeakReference 比 软引用更弱
只能存活到下一次 GC,GC 时回收
虚引用
PhantomReference 最弱的引用
不会对对象的生存造成影响,且不能通过引用获取到对象<br>
设置虚引用的唯一目的是对象回收时能接收到系统通知,常用于冰山对象回收(netty 本地字节缓存对象)<br>
对象内存布局
对象头
_markWord
32位系统 4字节,64位系统 8字节。hash(内存关联的 identityHashCode)/GC 等信息<br>不同标志位时,表达的数据不同<br>|标志位|状态|存储内容<br>| 001 | 未锁定 | 对象 hash 和分代年龄<br>| 101 | 可偏向锁 | 偏向线程 ID、偏向时间戳、对象分代年龄<br>| 000 | 轻量级锁 | 锁记录的指针<br>| 10 | 重量级锁 | 重量级锁的指针<br>| 11 | GC 标记 | 空,不需要记录信息<br>
_klassWord
32位系统 4字节,64系统 8字节,开启指针压缩后 4字节<br>指向类型对象的地址<br>
数组长度(只有数组对象才有)
int 类型长度,4字节
实例数据
填充
内填充和外填充
内填充是指在对象头与实例数据之间,实例数据中不同类型之间的填充
外填充是指整个对象数据填充完毕后不满足 8字节的整数倍时在数据最后的填充
JMM 内存模型
目的:屏蔽各种硬件和操作系统访问内存的差异,以实现 java 程序<b>在各种平台下达到一致的并发效果</b><br>或者说,定义程序中各个变量的访问规则,即在虚拟机中变量存储到内存和从内存中读取变量这样的底层细节<br><br>此处的变量包括实例实例字段,静态变量,数组元素,但不包括局部变量和方法参数(线程私有不被共享)
主内存和工作内存
主内存(可以类比为物理主内存,堆区部分区域)
所有变量存储在主内存
线程间变量的值传递必须通过主内存<br>
线程不能直接读写主内存的变量
工作内存(类比为高速缓存/寄存器,虚拟机栈部分区域)
每个线程有自己的工作内存
保存当前线程使用到变量的主内存的副本<br>
线程对变量的所有操作(读取,赋值等)都必须在工作内存中进行<br>
不能放弃其他线程的工作内存中的变量
交互操作
lock 作用<b>主内存</b>,把一个变量表示一个线程独占状态<br>
unlock 作用<b>主内存</b>,取消一个变量的独占状态
read 作用<b>主内存</b>,读取一个变量前往工作内存,供 load 使用
load 作用<font color="#c41230">工作内存</font>,接收 read 的变量保存到工作内存中<br>
use 作用<font color="#c41230">工作内存</font>,传递一个工作内存中的变量给执行引擎使用
assign 作用<font color="#c41230">工作内存</font>,接收执行引擎的值赋值给工作内存中的变量
store 作用<font color="#c41230">工作内存</font>,把工作内存中的一个变量传递到主内存去<br>
write 作用<b>主内存</b>,接收工作内存中传递出来的值保存到主内存中的变量
额外规则
lock/unlock 次数必须相等,才能完全释放一个变量(重入机制)
read/load,store/write 必须配对使用
最近的 assign 操作不能丢弃,最近变化的值必须同步回主内存
没有修改不能使用 assign
对象必须先定义在主内存中才能使用,先有 load/assign 才有 use/store
lock 操作会清空工作内存中对应变量的值,执行引擎使用时需要重新 load,使用后要 assign
不能 unlock 没有被 lock 的对象;不能 unlock 其他线程 lock 的变量<br>
对一个变量的 unlock 之前必须把此变量同步会主内存
volatile 最轻量级的同步机制
最轻量级的同步机制
两个语义
变量可见性
禁止变量重排序
对交互操作的影响
read/load/use 三个指令同时连续出现,不能插入其他指令
assign/store/write 三个指令同时连续出现,不能插入其他指令
可见性/原子性/一致性/有序性
可见性
当一个变量被一个线程修改了值,新值对其他线程是可以立即得知这个修改<br>
volatile
synchronized/Lock
final
一致性
多个线程获取的同一变量的值不一致的情况
原子性
一个操作或者多个操作<b>要么全部执行并且执行的过程不会被任何因素打断</b>,要么就都不执行
六大交互操作是原子的<br>
基础数据的读写
synchronized 块也具有原子性
有序性
本线程观察内部执行是有序的,线程内串行,线程内优化不影响先行发生
一个线程观察其他线程是无序的
指令重排序
主内存和工作内存同步延迟
多核执行 <br>一个线程在一个CPU 核心挂起,另一个线程在另一个 CPU 执行可能挂起,可能之前的线程挂起<br>
volatile、synchronized 保证有序性
happens-before 先行发生
两个操作之间的偏序关系,A 先行于 B,说明 B 能观察到 A 的变化
自带先行发生规则
1. 程序次序规则 线程内方法执行是顺序的,按照控制流程来说<br>
2. 监视器锁定规则 同一个对象的解锁操作总是发生于后一个上锁操作,时间纬度
3. volatile 变量规则 volatile 变量写操作总是时间上先行发生于该变量的读操作
4. 线程启动规则 线程 start 方法先行发生于线程内动作
5. 线程终止规则 线程所有操作早于线程终止检查
6. 线程中断规则 中断操作先行发生于中断检查
7. 线程终结规则 对象初始化早于对象终结方法 finalize
8. 传递性 A 先于 B, B 先于 C, 那么 A 先于 C
Java 与线程
线程类型
内核线程
直接由操作系统内核支持的线程叫内核线程
内核完成线程切换,内核通过调度器完成对线程的调度,以及线程到处理器的映射
可以看做内核的一个分身,支持多线程的内核叫多线程内核
轻量级进程(LightWeightProcess)
内核线程的高级接口,就是通常意义上的线程
每个轻量级进程都由一个内核线程支持,1:1 对应,是一对一线程模型
优点:由于每个LWP由内核线程支持,是一个独立的调用单元,阻塞也不影响进程的执行
缺点:<br>1. 基于内核,创建销毁操作需要进行代价较高的系统操作,用户态和内核态切换<br>2. 需要占用内核资源(如内核栈空间),支持数量有限
用户线程
定义
广义上,非核心线程都可以叫做用户线程,LWP 和内核线程一一对应,效率受限制
狭义上,完全定义在用户空间的线程库上,系统不能感知到线程存在的实现
用户线程的创建同步销毁调度都在用户态完成,不需要内核的参与。因此操作快速且消耗低<br>
进程与用户线程的对比关系为 1:N 线程模型
优点:不需要内核参与,速度和消耗很好
缺点:实现复杂,有些问题困难甚至无法解决(线程管理和调度,以及映射到CPU)<br>
线程实现方式
1. 内核线程实现
基于高级接口 LWP实现, 一对一的线程模型
2. 用户线程实现
基于用户线程实现,实现困难,越来越少使用用户线程实现了。一对多的线程模型
3. 用户线程+轻量级进程 的混合实现
即存在内核线程,也存在LWP
用户线程还是创建在用户空间,创建销毁切换依旧廉价,支持大规模用户线程并发<br>
LWP 作为内核线程和用户线程之间的桥梁,使用内核提供的调度器功能和CPU 映射功能<br>
用户线程需要通过 LWP 完成系统调用,降低进程被阻塞的风险<br>
用户线程和 LWP 比例不定,M:N 的关系,是多对多的线程模型<br>
Java 线程实现
Linux/Windows 下是 一对一的线程模型,一条Java线程映射到一个 LWP<br>
Solaris 系统支持多对多模型,所以 Java 在 Solaris 上同时支持一对一和多对多的线程模型
线程调度
定义:系统为线程分配使用的过程
调度方式
协同式<br>
线程执行时间由线程自己控制。<br>实现简单;但是时间不可控、容易系统崩溃
抢占式
系统分配执行时间,切换不由线程本身决定。<br>执行时间可控,线程阻塞不会导致整个进程阻塞,也不会导致系统崩溃<br>
线程优先级
优先级并不靠谱
Java 有 10个优先级,Windows 7个,Solaris 有 2^31 存在 多对一的情况<br>
系统能够调整优先级,此外工具也能够修改优先级
系统和Java线程状态
系统线程状态
New 新建 刚创建的、未启动的线程
Runnable 就绪态,获取了除 CPU 外的所有资源
Running 执行态,就绪态的线程获取 CPU 时间片后切换至执行状态。时间片耗完,切换回就绪态等待下一时间片的分配
Blocked 阻塞态,执行状的线程发生了某种暂停执行的事件,放弃CPU的执行时间,进入阻塞状态。比如竞争临界资源,等待IO等事件。<br>位于阻塞状态的进程,获取到等待资源后,将进入就绪状态等待CPU分配时间片。
Terminated 结束,完成执行逻辑后
Java 线程状态
New 创建后未启动
Runnable 运行,对应操作系统的 Ready 和 Running 两种状态
Thread.start
Waiting 等待中,不会获取 CPU 时间片,等待被其他线程显式唤醒
Object.wait
Thread.join
LockSupport.park
TimedWaiting 期限等待,不会获取 CPU 时间片,显示唤醒或者超时自动唤醒<br>
Thread.sleep
Object.wait(timeout)
Thread.join(timeout)
LockSupport.parkNanos(timeout)<br>
LockSupport.parkUntil(nanos)
Blocked 阻塞,等待获取排他锁,等待进入同步区块时就是处于阻塞状态
synchronized
notify/notifyAll 让等待的线程进入阻塞状态,可以竞争锁资源
Terminated 结束,已终止的线程状态,线程已结束执行了
run() 方法结束
线程安全和锁
定义:多线程访问一个对象,<b>无论多线程如何调度交换,在没有额外同步的情况下</b>,<br>调用这个对象的行为都可以获得正确的结果,那么这个对象是线程安全的<br>
线程数据分类
1. 不可变对象,线程安全的,如 基础数据类型和 String 对象
2. 绝对线程安全,如 Vector,多个安全方法一起使用并不安全,所以绝对不绝对
3. 相对线程安全,就是常说的线程安全。这类对象单独操作是安全的,连续操作需要额外的同步手段来保证正确性<br>如:Vector, Hashtable,Collections.synchronizedCollection 等
4. 线程兼容。本上不是线程安全,通过调用端同步保证同步保证并发情况下安全使用<br>非线程安全的类通常说的是这一类情况
5. 线程对立。不能再多线程环境下使用,如线程的 suspend/resume 方法
实现方式
1. 互斥同步(阻塞同步)<br>
悲观同步方案,有临界区、互斥量、信号量等方式
synchronize 是java 中最基本实现,通过一个引用对象和 monitorenter/monitorexit 指令实现
juc下 Lock 接口也能实现互斥同步
缺点: 由内核线程支持,导致阻塞和唤醒带来性能问题
2. 非阻塞同步
乐观并发策略
需要硬件支持
CAS 操作
3. 无同步方案
线程安全不一定需要同步,同步是保证竞争数据的正确性。不涉及共享数据的代码不需要同步<br>
1. 可重入代码(纯代码),响应式代码,没有共享数据,函数式编程<br>特点,不依赖堆上的数据和公共的系统资源,用到的都是传入的参数、不调用非可重入代码
2. 线程本地存储,保存线程独有的变量,线程间不能共享
锁优化
自旋锁
普通自旋锁
为了避免短时间内挂起和恢复线程,让线程忙循环(自选)一会。<br>超过自旋阈值将会走常规锁获取的过程(挂起等待恢复)
缺点:吞吐率降低
自适应自旋锁
根据前一次在同一个锁上自旋时间和锁持有者状态来决定<br>
如果自旋获取一个锁很少成功,那么将省掉自旋过程,避免浪费<br>
如果一个线程自旋完毕马上获取锁,jvm 任务自选完毕回再次获得锁,允许自旋更长时间<br>
锁消除
基于逃逸分析技术,检测到不存在共享数据竞争,消除锁<br>
锁粗化
同步范围扩大,消除内部同步
轻量级锁(通过对象头实现)<br>无竞争情况下CAS替代互斥量
加锁过程
1. <b>创建锁空间</b>:没有锁定的情况下进入同步块时(此时标志位位 01),虚拟机在当前线程的栈帧中创建名为锁记录的空间(Lock record)
2. <b>替换标记字</b>:虚拟机尝试 CAS 操作将对象头的 markWord 更新为指向锁记录地址的指针
3. <b>获取成功</b>:如果更新成功,那么该线程就拥有了这个对象的锁,并且 markWord 的锁标志位转变为 00(轻量级锁)<br>
4. <b>重入判断</b>:如果更新失败,虚拟机会检查对象头的 markWord 是否指向当前线程的栈帧。如果指向当前线程,直接执行同步快
5. <b>自旋重试</b>:如果不是指向当前线程栈帧,说明被其他线程持有,自旋重新获取,自旋一定次数后膨胀为重量锁
6. <b>升级重量锁</b>:膨胀为重量级锁时标志位转变为 10,此时 markWord 中存储的是指向重量级锁(OS底层的互斥量)的指针,阻塞等待锁的线程<br>
解锁过程
1. <b>替换标记字</b>:如果仍指向线程的锁记录,那么将锁记录的内容替换到 markWord 中,替换成功表示同步过程完成了<br>
2. <b>重量锁唤醒</b>:如果替换失败,说明 markWord 内容改变了,只能是锁升级的情况,此时需要唤醒挂起的线程
优化依据:绝大部分锁在整个同步周期内都是不存在竞争的
偏向锁(通过对象头实现)<br>无竞争情况下消除同步(和CAS)
加锁过程
1. 交换线程ID:可偏向锁对象第一次被线程获取时,CAS 操作线程 ID 记录到 markWord 中<br>
2. 去同步操作:操作成功后,持有偏向锁的线程进入该锁的同步块内,线程不执行任何同步操作<br>
3. 当其他线程尝试获取这个锁时,偏向模式结束(有重偏向设定,设置为其他线程)<br>
4. 根据对象是否处于锁定状态进行偏向撤销
5. 如果对象处于锁定状态,继续到下一个安全点判断是否执行完毕。<br>
6. 如果执行完毕,修改标志位 001,不可偏向。下一次同步调用走轻量级锁定流程
7. 如果没有执行完毕,升级轻量锁,执行轻量锁锁定过程<br>
重偏向:初始偏向线程外,重新偏向其他线程
需要注意的点
偏向锁启动有延迟,可配置
计算过 identity hashCode(与内存地址相关的 hashcode,原生 hashcode) 之后,不可偏向
编译和执行
编译过程
解析和填充符号表过程<br>
词法分析,将字符流转换为 token 集合<br>
语法分析,将 token 序列转换成 AST 语法树
填充符号表,符号表是地址分配的依据<br>
插入式注解处理器的注解处理过程<br>
读取/添加/修改 抽象语法树中的任意元素<br>
语义分析和字节码生成过程<br>
语义分析,对结构正确的源程序进行上下文有关性质的审查,如:<br>int a = 1; boolean b = false, char c = 2;<br>对于 int d = b + c 这种错误是通过语义分析来保证的<br>
1. 标注检查
2. 数据和控制流分析<br>局部变量是否赋值,每条路径都有返回值等等
3. 解语法糖 拆解
4. 字节码生成
clinit/init 在这个阶段加入到语法树中<br>
如果没有任何构造器,会生成和类访问权限一致的 init 方法
clinit 和 init 是代码收敛过程,会将多个块顺序收敛到对应方法
clinit 收敛类变量、静态代码块,并保证父类的 clinit 先执行
init 收敛父类构造函数调用、实例变量、非静态代码块、自身构造器调用
语法糖相关
泛型
参数化类型
C# 泛型,类型膨胀,是真实泛型
只存在与编译器,编译后泛型被擦除,替换为原生类型,裸类型,伪泛型
装箱拆箱
编译之后转换成对应包装和还原方法<br>
Integer.valueOf/Integer.intValue
增强 for 循环
迭代 iterator 实现
可变参数
封装成数组
解释器
解释执行字节码,平台无关,启动快,热点效率低
即时编译器
提高热点代码的执行效率,编译成平台相关的机器码,并进行优化
hotspot 内置两个即使编译器,client/server<br>
即时编译条件
* 多次被调用的方法<br>
* 多次被执行的循环体
编译的是方法体,发生在方法执行过程中,也称为栈上替换
判断方法
基于采样的热点探测,周期性检查栈顶方法
基于计数的热点探测,hotspot 采用的是这一种,两个计数器<br>
方法调用计数(方法计数)
1. 有现成编译结果就使用现有结果
2. 统计调用次数,超过阈值,提交编译请求,继续解释执行<br>
3. 编译完成后,方法调用地址被改成编译后的新地址
4. 一定时间不足阈值后会半衰计数,半衰可控
回边计数(方法内计数)
方法中循环体被执行次数,不衰减,统计绝对次数,溢出执行标准编译流程
控制流向后跳转的指令称为回边<br>
1. 有现成的编译结果用现成的
2. 两个计数之和是否满足阈值,超过提交编译请求
3. 稍微调小回边计数的值,以便继续解释执行
编译过程
编译优化
数组边界检查消除
方法内联<br>
逃逸分析
分析对象的动态作用域
方法逃逸,作为调用参数传递到其他方法<br>
线程逃逸,可以被外部线程访问/其他线程可以访问实例变量等<br>
优化方案
栈上替换
同步消除,不发生线程逃逸时
标量替换,不被外部访问时,不用创建对象,<br>
使用(执行引擎)
调用字节码
* invokestatic 调用静态方法
* invokespecial 实例 <init> 方法、私有方法、父类方法
* invokevirtual 所有虚方法
* invokeinterface 接口方法,运行时再确定一个实现该接口的对象
invokestatic/invokespecital 能调用的方法(也叫非虚方法),都可以再解析阶段唯一确定调用版本
其他方法(除去 final 方法,final 方法是非虚方法),称为虚方法。final 方法用 invokevirtual 调用,但是 final 方法不会被覆盖,版本唯一<br>
执行分派
变量类型
变量的静态类型,Human h = new Male() 中 Human 是 h 变量的静态类型或外观类型,<br><b>最终的静态类是编译器可知的</b>
变量的实际类型,上面 h 的实际类型为 Male
单分派/多分派
方法接受者和方法参数的数量称为宗量<br>单宗量选择执行方法为单分派<br>多宗量选择执行方法为多分派
静态分派(多分派)
依赖静态类型来定位方法执行版本的分派动作,称为静态分派<br>
方法重载是静态分派
静态分派发生在编译阶段,不是由虚拟机来完成的
通过参数临时修改静态类型可以选中重载版本 say((Male) h)
基元类型 包装类型 父类型 接口类型 依次上推查找重载版本
动态分派(单分派)
根据实际类型来定位执行方法版本的分派动作,叫做动态分派
重写是通过 invokevirtual 动态分派实现的
invokevirtual 指令实现动态分派步骤
1. 查找栈顶元素的实际类型
2. 能否找到方法签名一致的方法,检验权限,通过返回
3. 如果没找到,根据继承关系继续向上查找
4. 始终没找到则异常
虚拟机实现动态分派
invokevirtual 对应虚方法表,invokeinterface 对应接口方法表
用虚方法表索引来代替元数据检索以提高性能<br>
虚方法表存放着各个方法的实际入口地址
如果子类没有重写父类的某个方法,那么子类方法表中和父类该方法的入口地址是相同的,都指向父类的实现入口地址<br>
如果重写了父类方法,子类方法表中该方法指向的地址就是自己实现版本的入口地址
为了实现方便,父子类相同方法在方法表中的索引是一样的。当类型变换时,只需要变更查找的方法表即可<br>
类加载-连接-准备过程中,初始化方法表
JVM 监控和工具<br>
jps 查看正在运行的 java 进程信息
jstat 监视虚拟机各种运行状态信息
可显示本地和远程的信息
信息包括 类装载,内存,垃圾回收,JIT 编译等信息<br>
运行期定位性能问题的首选工具
jinfo 实时查看 JVM 配置信息<br>
jmap 堆快照信息,堆和永久代信息,空间使用率,使用的收集器等<br>
jstack 当前时刻线程快照,定位线程长时间停顿,如死锁<br>
JConsole
JVisualVM
常见问题:
CPU 飚高看栈,top 查看线程占用率高
内存占用高看堆
JVM 调优
目的:减少GC的频率和Full GC的次数,过多的GC和Full GC是会占用很多的系统资源(主要是CPU),影响系统的吞吐量。<br>特别要关注Full GC,因为它会对整个堆进行整理
调优目标<br>
GC 视角:(过多占用 CPU 资源)<br>1. 减少 GC 次数<br>2. 降低 GC 时间<br>
用户视角:<br>1. 更高吞吐量<br>2. 更少停顿时间<br>
调优手段
调整各内存区域的大小/比例
Eden/Survivor
<b>新生代设置过小</b>:<br>1. 新生代GC次数非常频繁,增大系统消耗;<br>2. 导致大对象直接进入旧生代,占据了旧生代剩余空间,诱发Full GC
<b>新生代设置过大</b>:(默认 1/3,一般不需要调整)<br>1. 新生代设置过大会导致旧生代过小(堆总量一定),从而诱发Full GC;<br>2. 新生代GC耗时大幅度增加<br>
<b>Survivor设置过小</b>:<br>导致对象从eden直接到达旧生代,降低了在新生代的存活时间<br>
<b>Survivor设置过大</b>:<br>导致 eden 过小,增加了GC频率<br>
老年代
<b>老年代太大</b>:<br>1. 导致新生代过小,新生代 GC 频繁<br>2. 老年代回收耗时大幅增加
<b>老年代过小</b>:频繁 Full GC
方法区
<b>方法区过大</b>:浪费空间<br><b>方法区过小</b>:频繁诱发 Full GC
堆内存
<b>堆内存过大</b>:浪费空间<br><b>堆内存过小</b>:GC 频繁
调整 GC回收器和策略
垃圾回收器选择
串行收集器(100M 内的小数据)
并行收集器(吞吐量优先)
并发收集器(响应时间优先)
常见指标
停顿时间
-XX:MaxGCPauseRatio=n
吞吐率
-XX:GCTimeRatio=n
常见问题汇总

Collect
Get Started

Collect
Get Started
Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

