Encoder-Decoder模型
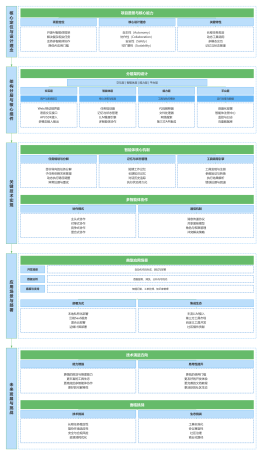
概述Encoder-Decoder模型是一种常见的深度学习模型,用于处理序列到序列的任务,如机器翻译、语音识别等。
结构Encoder-Decoder模型由两部分组成:编码器和解码器。编码器将输入序列转化为一个固定长度的向量,解码器则将该向量转化为输出序列。两个部分可以使用不同的神经网络结构,如循环神经网络、卷积神经网络等。
训练Encoder-Decoder模型通常使用最大似然估计进行训练。在训练过程中,将解码器的输出与目标序列进行比较,计算损失函数,通过反向传播更新模型参数。
应用Encoder-Decoder模型在机器翻译、语音识别、图像描述等任务中得到广泛应用。其中最著名的应用是Google的神经机器翻译系统。
改进为了提高模型性能,研究者们提出了许多改进的Encoder-Decoder模型,如Attention机制、PointerNetwork等。
注意事项在使用Encoder-Decoder模型时,需要注意过拟合、梯度消失等问题。可以通过正则化、dropout等方法进行缓解。
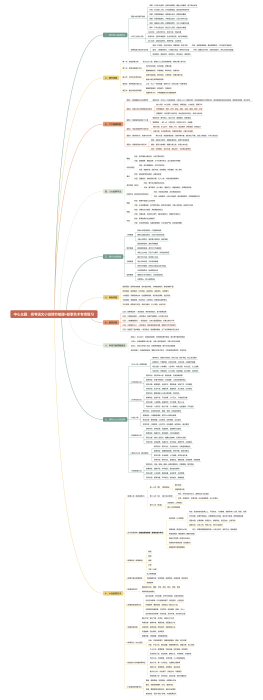
Transformer模型
Transformer模型是一种基于自注意力机制的神经网络模型,用于处理序列数据。
Encoder
Self-Attention
ScaledDot-ProductAttention
Multi-HeadAttention
PositionalEncoding
FeedforwardNetwork
Decoder
MaskedMulti-HeadAttention
Multi-HeadAttention
FeedforwardNetwork
OutputLayer
Training
LossFunction
Optimizer
LearningRateSchedule
Applications
NaturalLanguageProcessing
SpeechRecognition
ImageCaptioning
MusicGeneration
MachineTranslation
RecommendationSystems