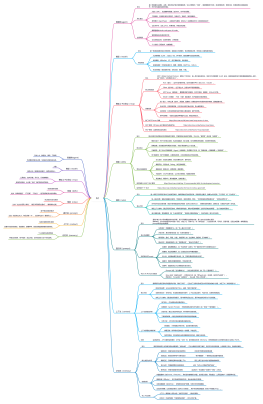
特征工程
特征工程-预处理<br>sklearn.preprcessing<br>
规范化<br>
MinMaxScaler 最大最小值规范化
Normailzer 将样本归一化为单位范数
StandardScaler 通过删除平均值和缩放到单位方差来标准化特征<br>
编码
LabelEncoder 把字符串类型的数据转化为整型<br>
OneHostEncoder 特征用一个二进制数字来表示<br>
Binarizer 为 数值型特征的二值化
MultiLabelBinarizer 多标签二值化
数据变换
Polynomisreatures 生成多项式和交互特征<br>
缺失值
imputer 用于完成缺失值的插补变压器
特征工程-特征提取<br>sklearn.feature_extraction
图像类
image.img_to_graph 像素到像素梯度连接的图形<br>
image.grid_to_graph 像素到像素连接的图形<br>
文本类
text.CountVectorizer 将文本转化为每个可出现个数的向量<br>
text.TfidfVectorizer 将文本转为tfidf值的向量<br>
text.HashingBectorizer 文本的特征哈希<br>
特征工程-特征选择<br>sklearn.feature_selection
Filter过滤器
VarlanceThreshold 删除特征值的方差达不到最低标准的特征<br>
子主题
SelectKBest 返回K 个最佳特征<br>
SelectPercentile 返回表现最佳的r%个特征<br>
Embedded 嵌入法
SelectFromModel 基于模型的特征选择<br>
特征工程-特征<br>sklearndecomposition
因子分析
FactorAnalysis 因子分析(FA)
模型训练
线性、广义线性模型<br>sklearn.linear_model
LinearRegression 普通最小二乘线性回归
LogisticRegression Logistic 回归(又名logit,MaxEnt)分类器<br>
朴素贝叶斯模型<br>sklearn.naive_bayes
GaussianNB 高斯朴素贝叶斯
MultlnomialNB 朴素贝叶斯分类器多项式模型
BernoulliNB 朴素贝叶斯分类器多变量伯努利模型
最近邻模型<br>sklearn.neighbors
KNeighborsClassifier 执行k-最近邻居的分类器投票
神经网络模型<br>sklearn.neural_network
neural_network.MLPClassifier([]) 多层感知器分类器
neural_networkMLPRegressor([]) 多层感知器回归
SVM模型<br>sklearn.svm
SvC C支持向量分类
LinearSVC 线性支持向量分类
决策树<br>sklearn.tree
DecisionTreeClassifier 决策树分类器
DecisionTreeRegressor 决策树回归
聚类 <br>sklearn.cluster
KMeans k均值聚类
SpectralClustering 将聚类应用于对规范化控普拉斯算子的投影
模型选择<br>sklearn.model_selection
交叉验证(原cross_validation)
KFoldK-Fold 交叉验证迭代器。接收元素个数、fold 数、是否清洗<br>
LeaveOneOut LeaveOneOut 交叉验证迭代器
LeavePOut LeavePOut 交叉验证迭代器
LeaveOneLabelOut
LeavePLabelOut
数据集分割函数(原cross_vaildation)
train_test_split 分离训练集和测试集
模型验证(原cross_validation)
cross_val_score 通过交叉验证评估分数
cross_val_predict 为每个输入数据点生成交叉验证的估计<br>
permutation_test_score 评估其有置换的验证分数的意义<br>
learning_ourve 学习曲线
validation_curve 验证曲线
超参数优化(原grid_search)
GridSearchCV 搜索指定参数网格中的最佳参数
ParmeterGrid 参数网格
ParameterSampler 用给定的分布生成参数的生成器
RandomizedSearchCV 超参数的随机搜索
模型组合<br>sklearn.ensemble
BaggingClassifier Bagging 分类器组合
BaggingRegressor Bagging 回归器组合
AdaBoostCalssifier AdaBoost 分类器组合
AdsBoostRegressor Adaboost 回归器组合
OradiendBoostingCalssifier 分类器组合
OradiendBoostingRegressor 回归器组合
RandomTreeClassifier 随机森林分类器组合
RandomTreeRegressor 随机森林回归器组合
VationgClassifiter 多模型投票融合器
模型评估<br>sklear.metrics
回归结果度量
explained_varcance_score 可解方程的回归评分函数
mean_ebsolute_error 平均绝对误差
mean_squared_error 平均平方误差
分类结果度量
accuracy_score 分类准确度
condusion_matrix 分类混淆矩阵
classification_report 分类报告
precision_recall_fscaor_support 计算精确度、召回率、1. 支持率
jaccard_simliarty_score 计算jceard 相似度
hamming_loss 计算汉明损失
zero_one_loss 0-1损失
hinge_loss 计算hinge 损失
log_loss 计算log 损失
聚类的度量
adjusted_mutual_info_score 调整的互信息评分
silhouette_score 所有样本的轮廓系数的平均值
silhouetle_sample 所有样本的轮廓系数
多标签的度量
coverage_error 函数误差
label_ranking_average_precision_score 计算基于排名的平均误差()