Transformer
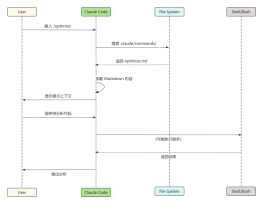
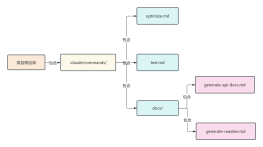
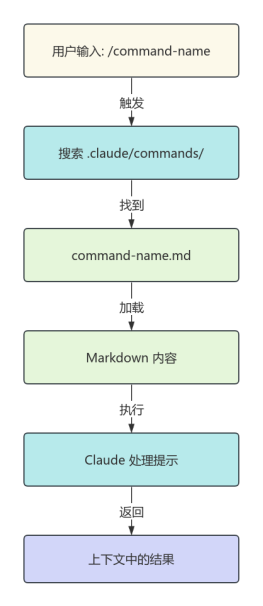
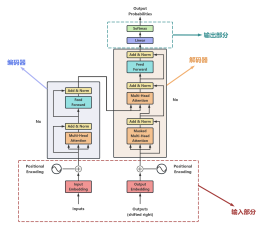
2025-06-25 09:01:52 6 举报Transformer深度学习模型,最初在自然语言处理领域取得了革命性的进展。它通过使用自注意力机制(Self-Attention)来捕捉序列内元素之间的依赖关系,而不依赖传统的递归网络结构。Transformer模型的设计被认为是先进的,且对后续的研究和技术发展产生了深远的影响;在机器翻译、文本摘要、问答系统等应用中表现出色,其开放式的预训练和微调模式也显示了强大的灵活性和适应性。
模板推荐
作者其他创作
大纲/内容





0 条评论
下一页