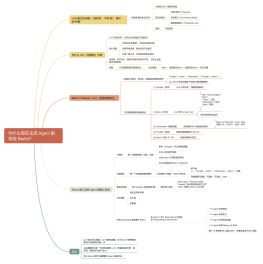
__init__:初始化日志容器
def __init__(self, task_id: str):<br> self.task_id = task_id # 任务唯一标识(如 UUID)<br> self.steps = [] # 存储每一步的详细日志<br> self.start_time = datetime.now() # 记录任务开始时间(用于计算总耗时)
task_id:将日志与具体任务绑定,方便后续回溯
start_time:自动记录启动时间,无需手动传入。
log_step:记录单步执行细节(核心方法)
def log_step(self, step: int, tool_name: str, tool_args: dict,
result_status: str, token_count: int, duration_ms: int):
详细参数
日志内容结构化存储
entry = {
"task_id": self.task_id,
"step": step,
"timestamp": datetime.now().isoformat(), # 精确到毫秒的时间戳
"tool": tool_name,
"args": tool_args,
"result_status": result_status,
"token_count": token_count,
"duration_ms": duration_ms
}
self.steps.append(entry)
timestamp:自动记录当前时间,方便按时间线复盘。
全量存储:把 “输入(tool_args)、输出状态(result_status)、成本(token_count)、效率(duration_ms)” 全部记录,无死角
实时调试打印
print(f"[{step:02d}] {tool_name}({tool_args.get('query', '')[:40]}) → {result_status} | {token_count} tokens | {duration_ms}ms")
在控制台实时打印极简日志,方便开发调试时一眼看到进度。
step:02d:补零对齐(如 01、02),更美观
[:40]:关键词太长时截断,避免刷屏。
为什么要记录 duration_ms
当某步花了 8 秒但结果是空的,通常意味着超时重试 —— 帮你判断是网络问题还是关键词问题”
场景 1:duration_ms=8000(8 秒)+ result_status=empty_result → 大概率是网络超时(工具内部重试了多次后放弃)
场景 2:duration_ms=500(0.5 秒)+ result_status=empty_result → 大概率是关键词问题(搜索太快但没结果)
价值:通过 “耗时 + 状态” 的组合,快速定位故障根因
summary:生成任务健康度摘要
核心指标计算
total_steps = len(self.steps) # 总步数<br>loop_steps = sum(1 for s in self.steps if s["result_status"] == "loop_detected") # 循环步数<br>failed_steps = sum(1 for s in self.steps if s["result_status"] not in ("ok", "loop_detected")) # 失败步数
摘要字典详解
return {
"task_id": self.task_id,
"total_steps": total_steps, # 总执行步数
"effective_steps": total_steps - loop_steps, # 有效步数(排除循环)
"loop_rate": loop_steps / total_steps if total_steps else 0, # 循环率(越高越容易卡死)
"tool_fail_rate": failed_steps / total_steps if total_steps else 0, # 工具失败率(越高越不稳定)
"peak_tokens": max(s["token_count"] for s in self.steps) if self.steps else 0, # Token 峰值(用于评估成本上限)
"total_duration_s": (datetime.now() - self.start_time).total_seconds() # 总耗时(秒)
}
参数
多维度分析:summary 不仅看 “成功 / 失败”,还看 “效率、成本、健康度”。