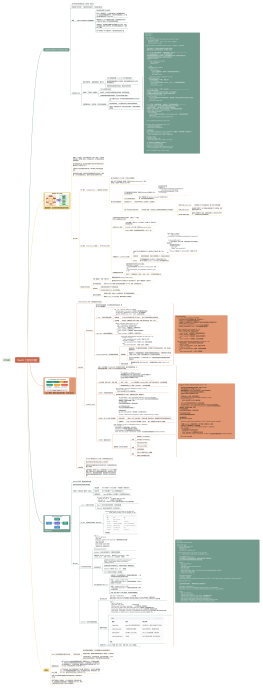
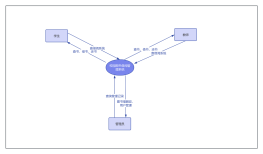
结合了 LLM(大语言模型)的决策能力、工具调用能力和之前定义的 EvolvingReport 记忆管理,模拟人类 “提出问题→调研→整合→再调研” 的研究过程
1. 函数概览
async def iter_research(query: str, tools: ToolSet, max_steps: int = 30) -> str:
定位
整个 Deep Research Agent 的核心调度器
参数
query
用户的原始研究问题(如 “2026 年 AI Agent 在银行的应用前景”)
tools
可用工具集(如搜索、网页抓取、计算器等)
max_steps
最大研究步数(防止无限循环,默认 30 步)
2. 初始化:启动研究引擎
report = EvolvingReport()<br>report.current_focus = query # 初始焦点 = 用户原始问题<br>report.open_questions = [query] # 初始待办问题 = 用户原始问题
创建一个 “空白记忆本”,并把用户的问题作为初始研究起点
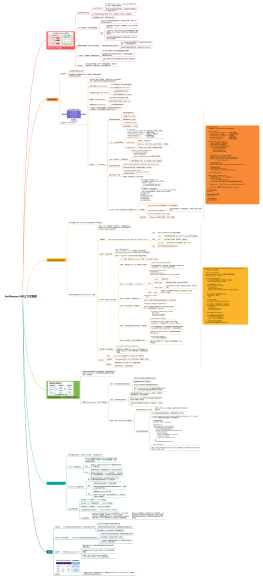
3. 主循环:迭代研究(核心逻辑)<br>
一个 for 循环,最多执行 max_steps 次,模拟 “一步步深入研究” 的过程
步骤 1:构建当前上下文(给 LLM 看的 “记忆快照”)
context = report.to_prompt_context()
把之前的研究成果(已确认事实、待解决问题、当前焦点)格式化为字符串,让 LLM 知道 “目前研究到哪了”
步骤 2:让 LLM 做决策(“下一步该干什么?”)
action = await llm.decide_action(
context=context,
available_tools=tools.list(),
system_prompt=ITER_RESEARCH_SYSTEM_PROMPT
)
输入<br>
available_tools
当前可用的工具列表(如 “搜索”“抓取网页”)
system_prompt
给 LLM 的指令(如 “你是一个研究员,请决定下一步用什么工具”)
输出
action
决策结果,如 “调用搜索工具查‘AI Agent 银行案例’” 或 “研究已充分,可以结束”
步骤 3:终止检测 1(“研究够了吗?”)
if action.type == "finish":
break
如果 LLM 判断 “信息已经足够回答原始问题”,主动跳出循环
步骤 4:执行工具调用(“动手查资料”)
observation = await tools.execute(action)
根据 LLM 的决策,实际调用工具(如执行搜索、抓取网页),并获取原始结果(observation)
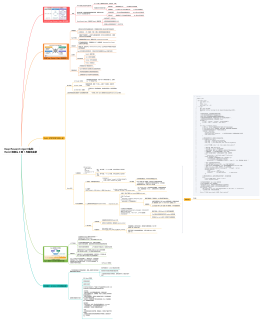
步骤 5:从原始结果中提取 “有效发现”(关键步骤)
new_findings = await llm.extract_findings(
action=action,
observation=observation,
current_report=context
)
report.update(new_findings)
把 “刚才做了什么(action)”“查到了什么 raw 数据(observation)”“之前的研究状态(context)” 喂给 LLM。
让 LLM 做信息蒸馏:从 raw 数据里提取 “新确认的事实”“解决了什么旧问题”“发现了什么新子问题”“下一步焦点该移到哪”
调用 report.update(new_findings),把蒸馏后的信息更新到 “记忆本” 里
步骤 6:终止检测 2(“所有子问题都解决了吗?”)
if not report.open_questions:
break # 所有子问题都已解决
如果 “待办问题列表” 空了,说明所有子问题都被解决,研究自然结束。
4. 最终输出:生成完整报告<br>
return await llm.synthesize_report(report)
循环结束后,把完整的 EvolvingReport(包含所有事实、问题追踪)喂给 LLM,让它写一篇结构清晰、有逻辑的最终研究报告
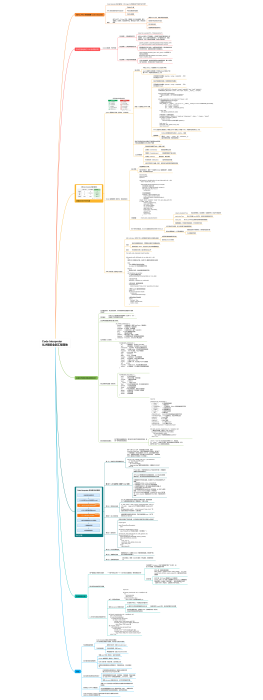
设计亮点<br>
异步化
async/await 让工具调用和 LLM 交互可以并发,提高效率
记忆增强
EvolvingReport 解决了 LLM“上下文窗口有限、容易遗忘” 的问题
智能终止
双重终止条件(LLM 主动 finish + 无待解决问题)
既保证研究充分,又避免浪费资源