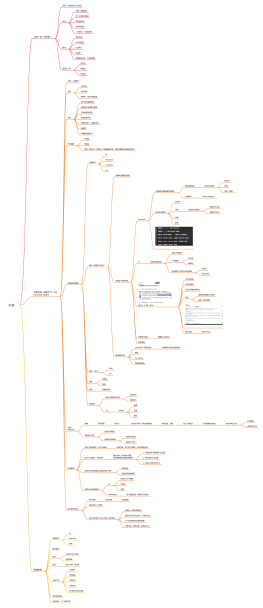
一、核心命令分类与原理(关联底层数据结构)
1. 键(Key)操作命令
<b>常用命令</b>:DEL key(删除键)、EXISTS key(判断键存在)、EXPIRE key seconds(设置过期时间)、TTL key(查看剩余过期时间)
<b>原理</b>:Redis 用全局哈希表(dict)存储键值对,键为字符串(SDS),DEL 直接删除哈希表中键对应的节点;EXPIRE 会将键存入过期字典(单独的dict),记录过期时间,定期删除或惰性删除。
2. 字符串(String)命令
<b>常用命令</b>:SET key value(设值)、GET key(取值)、INCR key(自增)、APPEND key str(追加)
<b>原理</b>:底层用 <b>SDS(简单动态字符串)</b> 存储,兼容C字符串但支持动态扩容、二进制安全。INCR 基于SDS的整数编码(若值为整数),通过原子操作实现自增,避免并发问题。
3. 哈希(Hash)命令
<b>常用命令</b>:HSET key field value(设字段值)、HGET key field(取字段值)、HKEYS key(获取所有字段)、HDEL key field(删除字段)
<b>原理</b>:底层用 <b>哈希表(dict)</b> 或 <b>压缩列表(ziplist,小数据优化)</b> 存储。HSET 会先检查哈希表是否需要扩容(负载因子>1),通过链地址法解决哈希冲突;小数据时用ziplist节省内存(字段-值连续存储)。
4. 列表(List)命令
<b>常用命令</b>:LPUSH key value(左插)、RPOP key(右删)、LRANGE key start end(获取区间元素)
<b>原理</b>:底层用 <b>双向链表(linkedlist)</b> 或 <b>压缩列表(ziplist,小数据)</b> 存储。LPUSH/RPOP 操作链表头尾指针(O(1));LRANGE 需遍历链表(O(n)),ziplist则通过偏移量计算位置。
5. 集合(Set)命令
<b>常用命令</b>:SADD key member(添加元素)、SMEMBERS key(获取所有元素)、SINTER key1 key2(交集)
<b>原理</b>:底层用 <b>哈希表(dict,value为null)</b> 或 <b>整数集合(intset,元素为整数且数量少)</b>。SADD 通过哈希表快速去重(O(1));SINTER 遍历较小集合,检查元素是否在其他集合中。
6. 有序集合(ZSet)命令
<b>常用命令</b>:ZADD key score member(添加带分数元素)、ZRANGE key start end(按分数升序取元素)、ZSCORE key member(获取分数)
<b>原理</b>:底层用 <b>跳表(skiplist)+ 哈希表</b> 存储。跳表按分数排序(支持范围查询,O(logn)),哈希表映射member到score(O(1)查分数)。ZADD 需同时更新跳表和哈希表。
7. 事务与原子命令
<b>常用命令</b>:MULTI(开始事务)、EXEC(执行事务)、WATCH key(监视键,防止并发修改)
<b>原理</b>:Redis 事务为“批量执行+隔离性”,不支持回滚(仅缓冲命令,EXEC 时一次性执行)。WATCH 基于乐观锁,通过检测键的版本号变化决定是否取消事务。
二、核心原理总结
<b>单线程模型</b>:所有命令在单线程中串行执行,避免线程切换开销,依赖IO多路复用(epoll/kqueue)处理并发连接。
<b>数据结构优化</b>:根据数据大小/类型动态选择底层结构(如ziplist、intset),平衡性能与内存占用。
<b>原子性保障</b>:单个命令天然原子(单线程执行),复杂操作可通过事务或Lua脚本实现原子性。