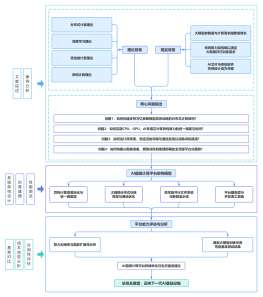
Llama 3模型架构图
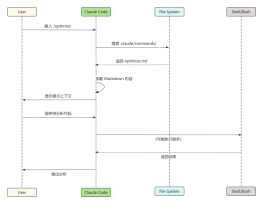
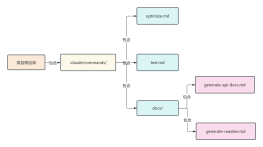
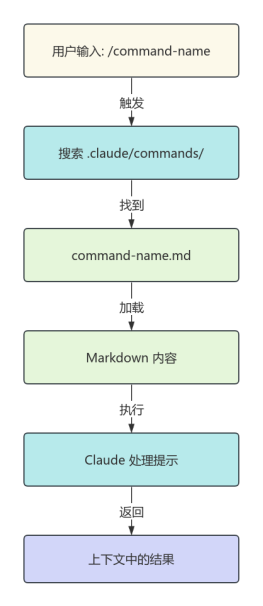
2026-02-02 20:21:40 0 举报Unlocking SOTA Performance: Inside the Llama 3 Architecture Dive into the structural brilliance of Meta's Llama 3, the open-source LLM redefining industry standards. This visualization deconstructs the model's high-performance backbone, featuring a highly optimized Decoder-only Transformer architecture. Key architectural highlights include Grouped Query Attention (GQA) for superior inference speed without sacrificing quality, Rotary Positional Embeddings (RoPE) for robust context handling, and the SwiGLU activation function for enhanced learning capacity. Whether you are an AI researcher or a curious developer, understanding these core modules—visualized here from global data flow to granular tensor operations—is essential for mastering the next generation of GenAI. #Llama3 #AIArchitecture #DeepLearning #LLM #MetaAI #DataScience #GQA #Transformer
模板推荐
作者其他创作
大纲/内容




0 条评论
下一页